We learned that basic object recognition terminologies in computer vision - object detection, semantic segmentation, instance segmentation.
In Biomedical field, the instance segmentation are frequently used such as detecting tumors based on radiography, lesion segmentation, etc. What is important here, in biomedical data, is that the output should include localization. We should have a predicted class label for every pixel.
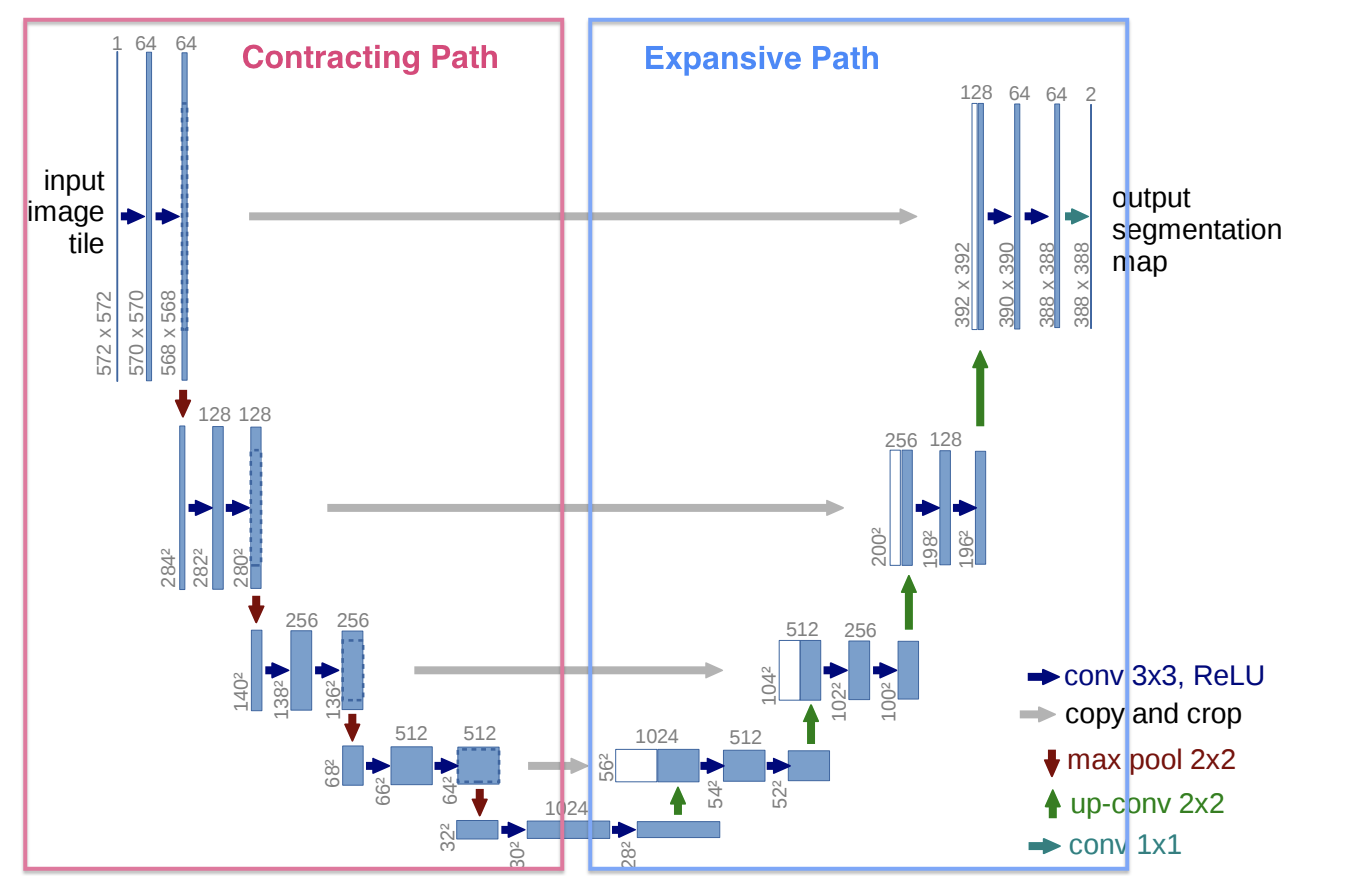
UNet borrows ideas from “Fully Convolutional Network(FCN)”. Instead of Fully Connected (FC) layers, the network replaced them with fully convolutional layers (Conv with 1 x 1) to conserve the context information of the input image. Also, due to FCN, they can handle with any input size - no need to take actions to fit the required input size of FC layer.t
Modules
- Contracting Path
- Works as an Encoder, consisting of Conv layers
- Captures contexts of the input image
- After each max-pooing step, it doubles the number of feature channels, allowing the network to propagate context information to higher resolution layers.
- Expanding Path
-
Works as a Decoder, consisting of Upsampling and Conv layers
-
Skip-Connection Concatenate: Concate the upsampled feature map and the one at each contracting step
Skip-Connection Concatenate?
While downsampling and upsampling the input image, “pixel” information is highly likely to be lost - not what Biomedial fields aim for. However, with the concatenation process, it directly delivers important features from encoding steps to decoding steps, allowing the network to predict more precisely at the pixel level.
Overlap-tile strategy
Due to FCN instead of FC layers, we discussed that we can handle with any input size. However, if the input image is way too big, we should divide the input, predict for all divided image and combine them afterwards. In the figure below, we can see that the whole image are separated, blue and red, and predicted separately, yellow and green. (The right side is the segmented output)
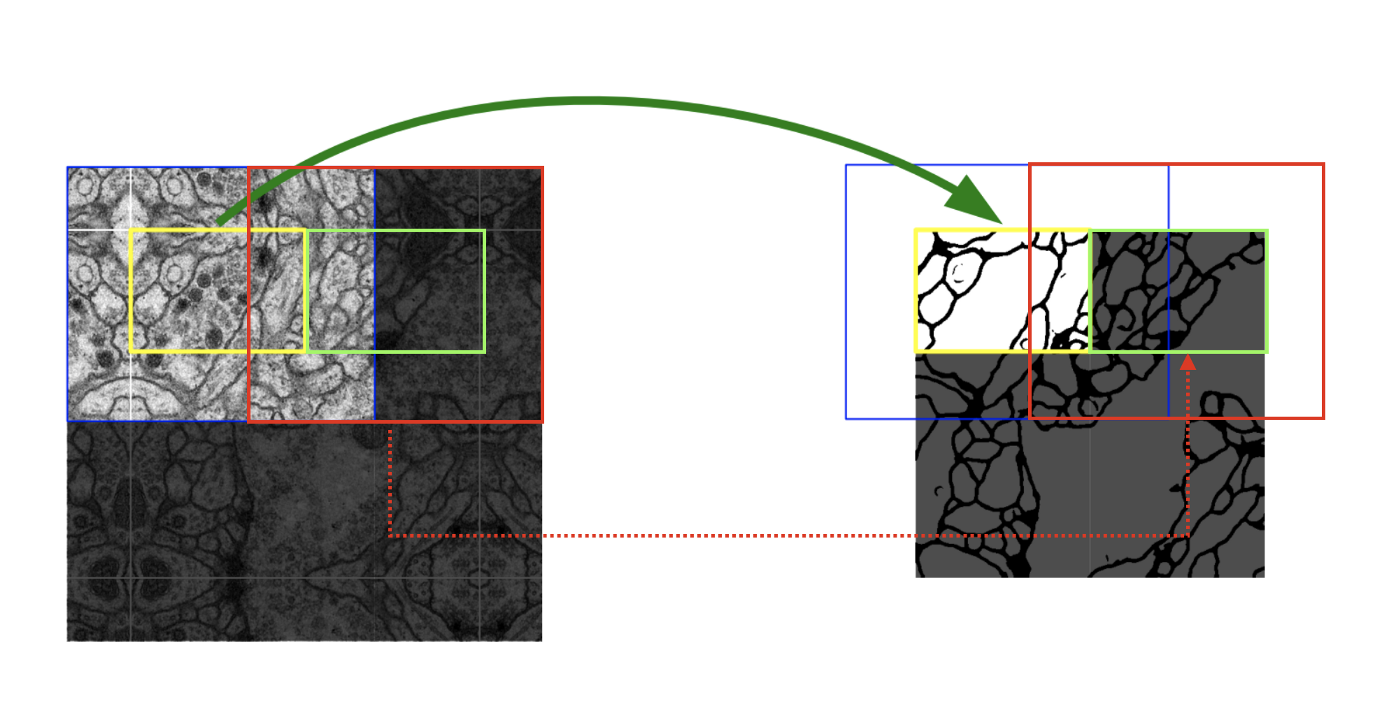
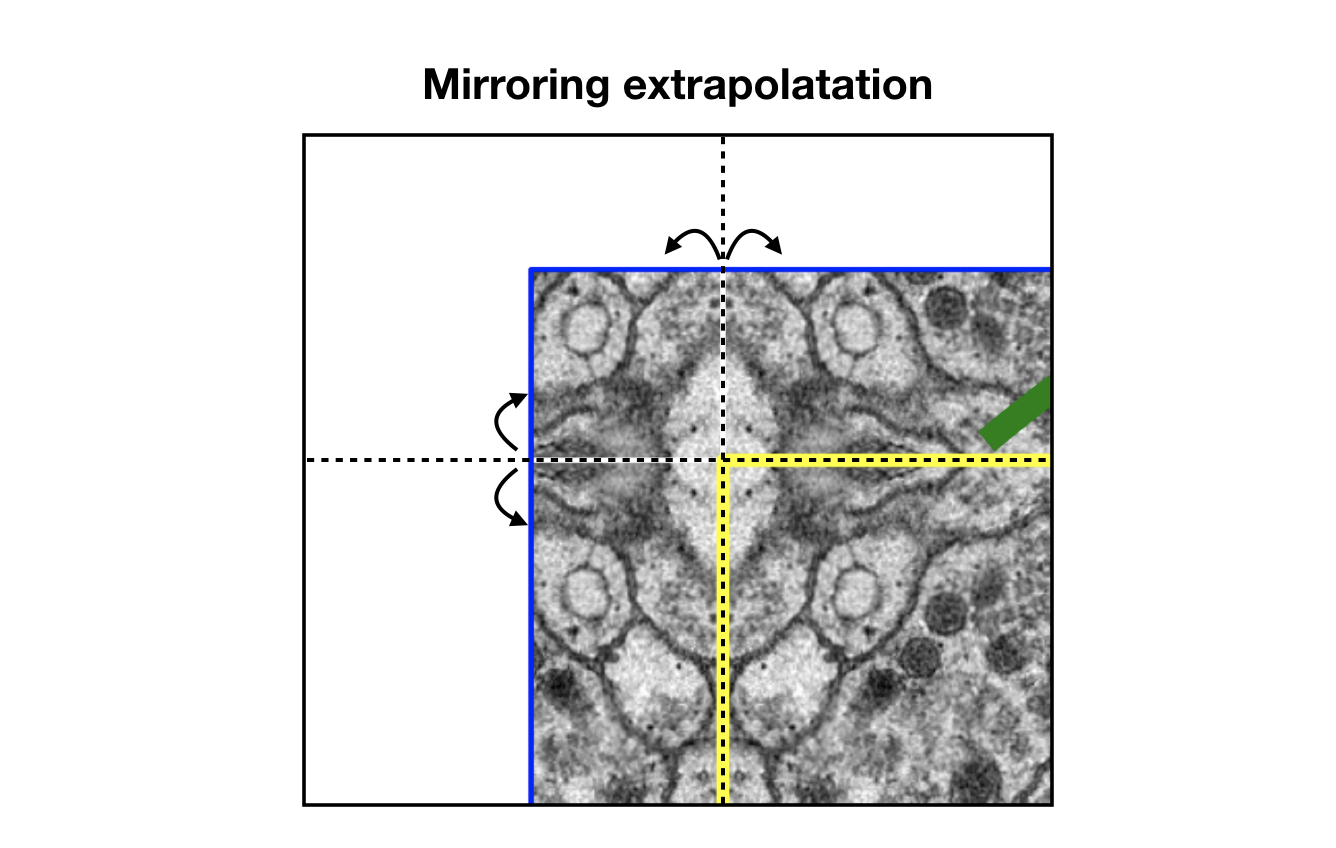
In details, the yellow area requires data within the blue area as input, since there is no padding at encoding steps, resulting in smaller output size than the actual input size (compare blue and yellow size). Overlap-tile strategy extraploates missing input data with mirroring, like
Elastic Deformation Data Augmentation
They overcome the lack of training data to yield good model performance by data augmentation - that we covered here. Smooth deformations are done for trainind data, using random displacement vectors.
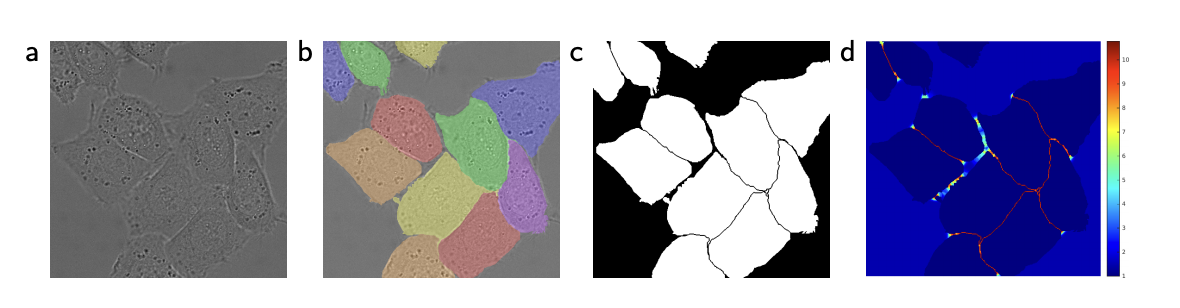
Separation of Touching Objects
Look at the picture below. (a) is a raw image and (b) is ground truth segmentation. In instance segmentation problem, it is hard to detect the borders between instances but surely important. In this paper, they apply a weight map to separate touching objects. The weight map is: $ w(\mathbf{x})=w_{c}(\mathbf{x})+w_{0} \cdot \exp \left(-\frac{\left(d_{1}(\mathbf{x})+d_{2}(\mathbf{x})\right)^{2}}{2 \sigma^{2}}\right) $
I am not going to cover the weight map in details but just inform you that this reflects the distance to the border, thus weighing the border line.
Many papers came out based on the UNet structure and even performs pretty good in biomedical segmentation problems today. Maintaining the U-shaped structure consisting of encoders and decoders, they take variants to encoders and decoders depending on problems.
SOCAR, a mobility startup in South Korea implemenets the UNet to detect car damage for their service. Probably interesting for you to read :) https://tech.socarcorp.kr/data/2020/02/13/car-damage-segmentation-model.html