Today, we are going to cover Sequence to Sequence Learning with Neural Networks, 2014.
Traditional DNNs improved the fields of machine translation, speech recognition ,etc remarkably. However, the traditonal DNNs can only handle fixed dimension of input and outputs, which is a critical flaw, especially in translating a sequence where the input and output dimensions are unknown.
Architecture
Let’s look at Seq2Seq architecture.
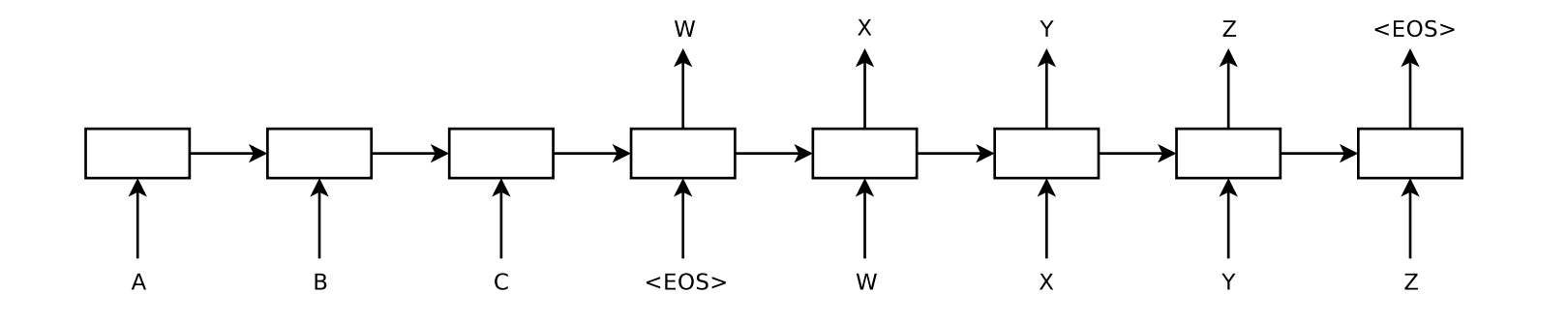
It seems like one long RNN but they use two LSTM as the encoder and decoder respectively. In this example, the model takes a sentence “ABC” as an input and translate into “XYZ” as an output. The encoder reads “A”, “B”, “C” sequentially then the encoder creates a large fixed-dimensional vector. When “
Why LSTM?
Compared to tradional RNNs, LSTMs can reflect the long-term dependency. As a sentence gets longer, the model is highly likely to forget information from early stages.
Three findings of this paper:
-
Two different LSTMs
-
Deep LSTMs significantly outperformed shallow LSTMs
-
Reversing the order of the words improved the model performance
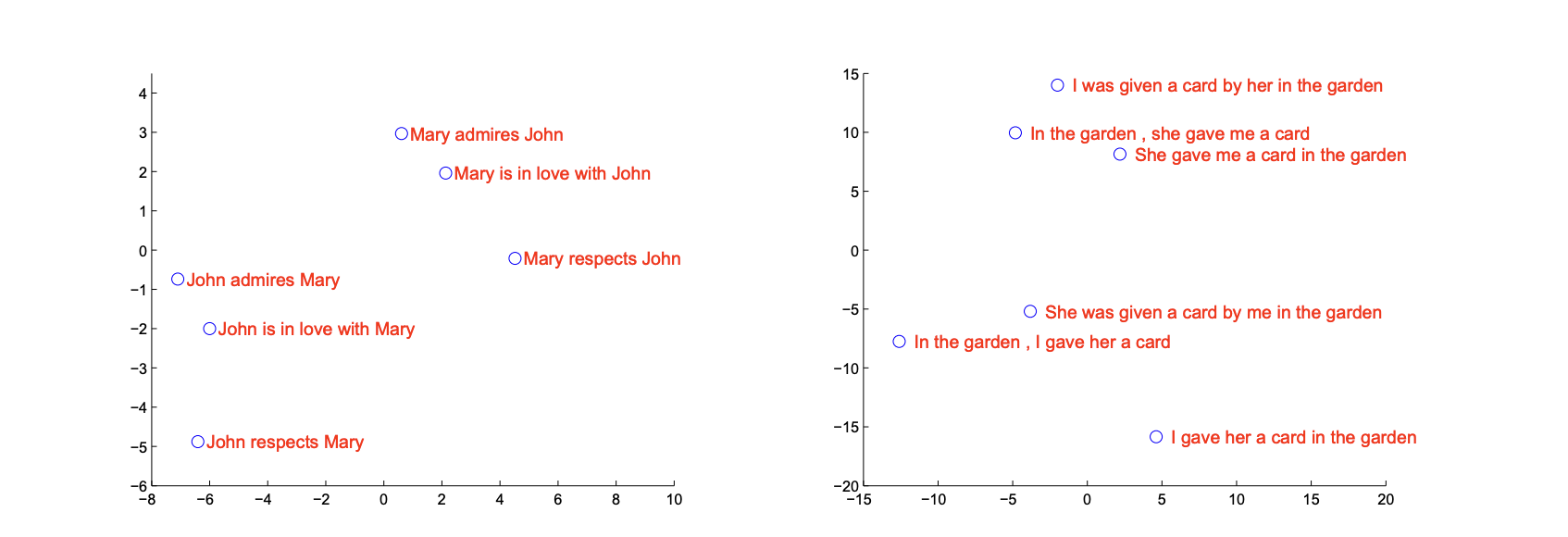
The above figure shows a 2D projected LSTM hidden states. Sentences that are predicted to be similar are close to each other. The result shows that the model is robust to active/passive voice. ‘She was given a card by me …’ and ‘In the garden, I gave her a card’ are located close, meaning that the model can learn that active/passive words eventually share same meaning. However, I gave her a card in the garden is pretty far from In the garden, I gave her a card. We can figure out that the model is sensitive to the word orderings, probably due to the LSTM structure. Thus, this paper suggests that reversing the order of the words improved the model performance, which makes sense.
Well, seq2seq model seems to be overwhelmed by Transformer and this post might be interesting if you are wondering the future of seq2seq model.