Scale-Invariant Feature Transform (SIFT) is an algorithm to extract image features that are robust to its image size or rotation. SIFT measures similarities between images and can be applied to image retrieval problems.
Let me see…
In the right picture with a red car, SIFT extracts features of the object (red car) and find whether the left image has the same object (car) or not by its extracted features regardless of its size or rotation.

1. Scale-space Extrema Detection
Potential location for finding features
Resize the original image to create an image pyramid,
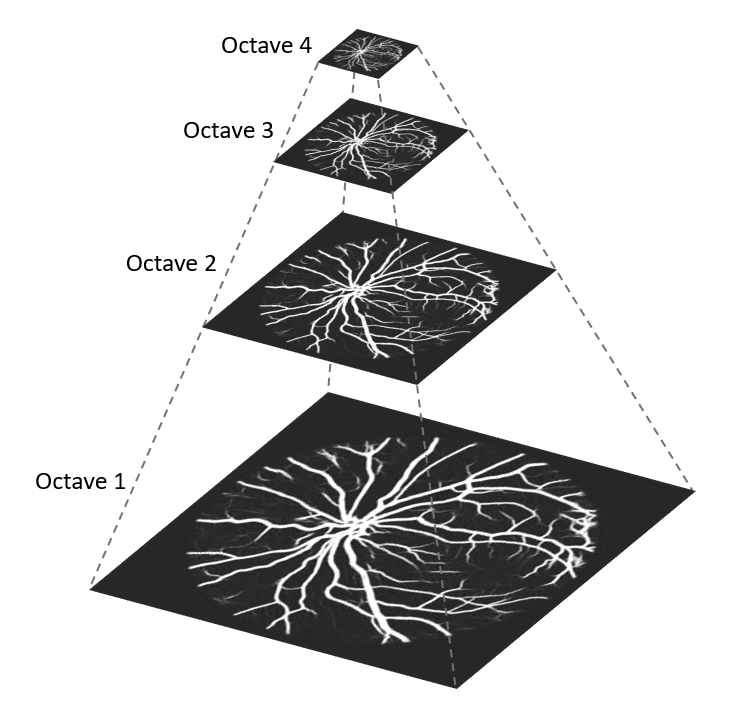
Apply a gaussian blur to each image with different $\sigma$ settings. The higher the octave is, the larger the $\sigma$ value. Definitely images located at higher octave seem much blurry.

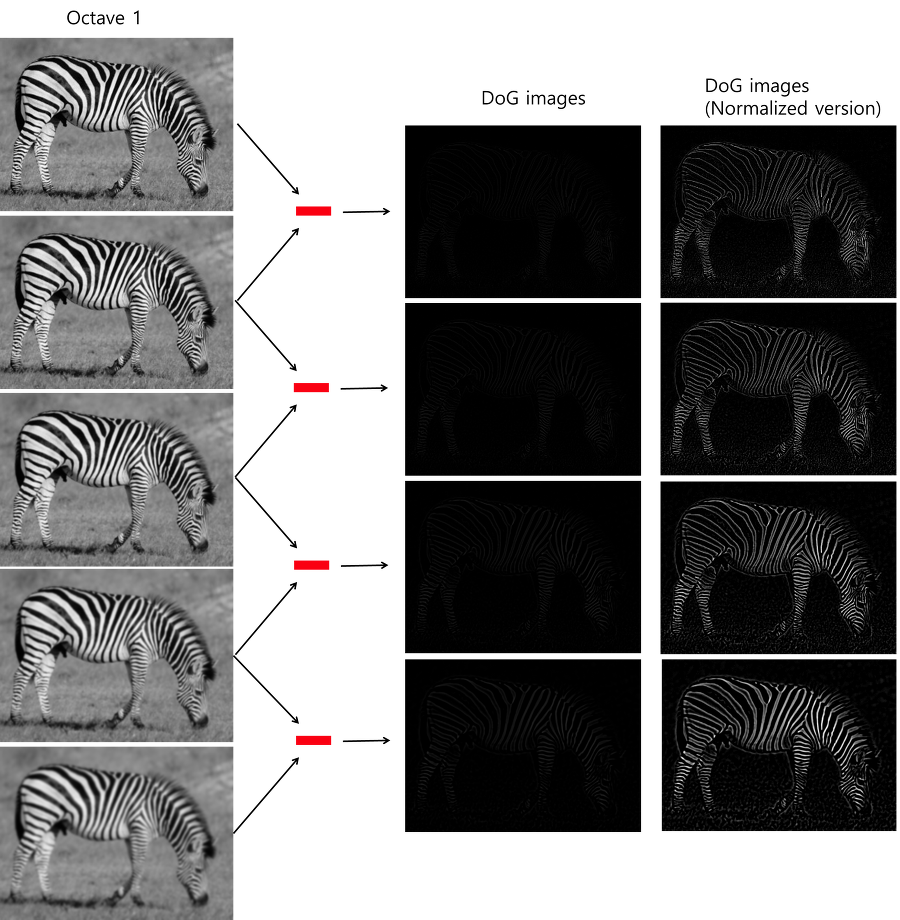
With those blurred images, let’s find out Difference of Gaussians (DoG). Take a difference between image pairs with different $\sigma$ values at one octave.
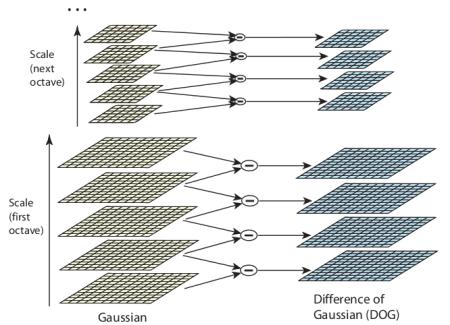
DoG ends up conveying edge and corner features (local extreme) of a given image.
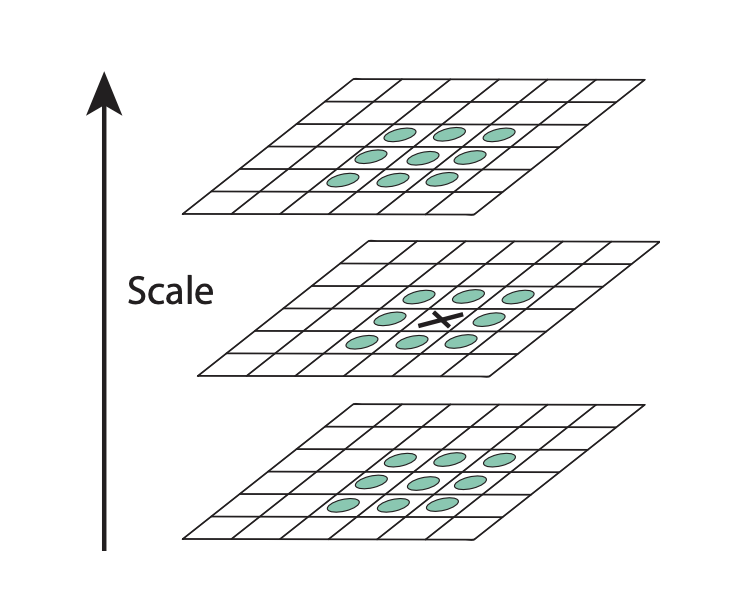
In details, we can detect local extremes in a pixel with neighboring pixels with different scale. In the above figure, we compare three DoG with different scales and tell whether the black x value is extreme based on neighboring pixels, 26 in total. If the black on is the maximum/minimum among 26 pixels, then we call it keypoints.
2. Keypoint Localization
Get rid of less important keypoints. If it has a too low contrast point value or lay on an edge, drop it.
Keypoints at this step are invariant to image scale.
3. Orientation Assignment
Next, assign direction to keypoints to find out rotation-invariant keypoints.
Slide a window onto a keypoint and calculate gradient orientations and size of every pixel in a given window. Pixels closer to the keypoint would have larger gradient values.

Then, we divide 360 degrees into 36 blocks (every 10 degree) around the keypoint and get weighted gradient values for each block. See the histogram below:
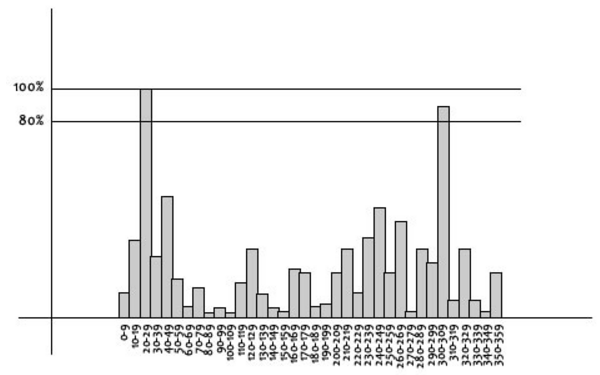
The orientation of the highest bin is the keypoint orientation and if it is over 80%, we also recognize it as a keypoint direction, two keypoints in total.
4. Keypoint descriptor
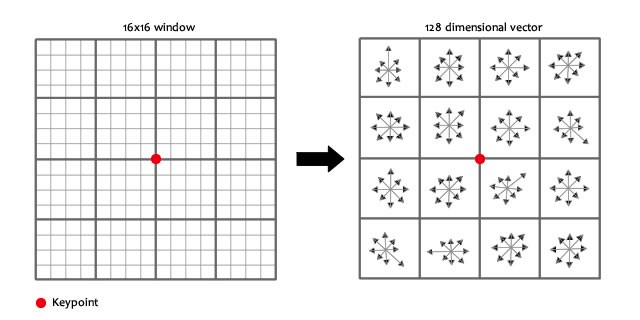
Finally, the keypoints we got contains location, scale and orientation information and insensitive to scale and rotation. To describe those keypoints, set 16 by 16 windows (each block = 4 by 4 windows) around the keypoint and draw histograms with 8 bin in each block. Then we have $448 = 128$ bins, a feature vector of our keypoint.
Reference
- https://bskyvision.com/21
- https://medium.com/data-breach/introduction-to-sift-scale-invariant-feature-transform-65d7f3a72d40
- https://ballentain.tistory.com/47