This is a class summary of AAI5003, 2021 spring semester lectured by Jinyoung Yeo at Yonsei University.
Model Structure
The upper part is the model flow of RNN and the bottom part is LSTM.
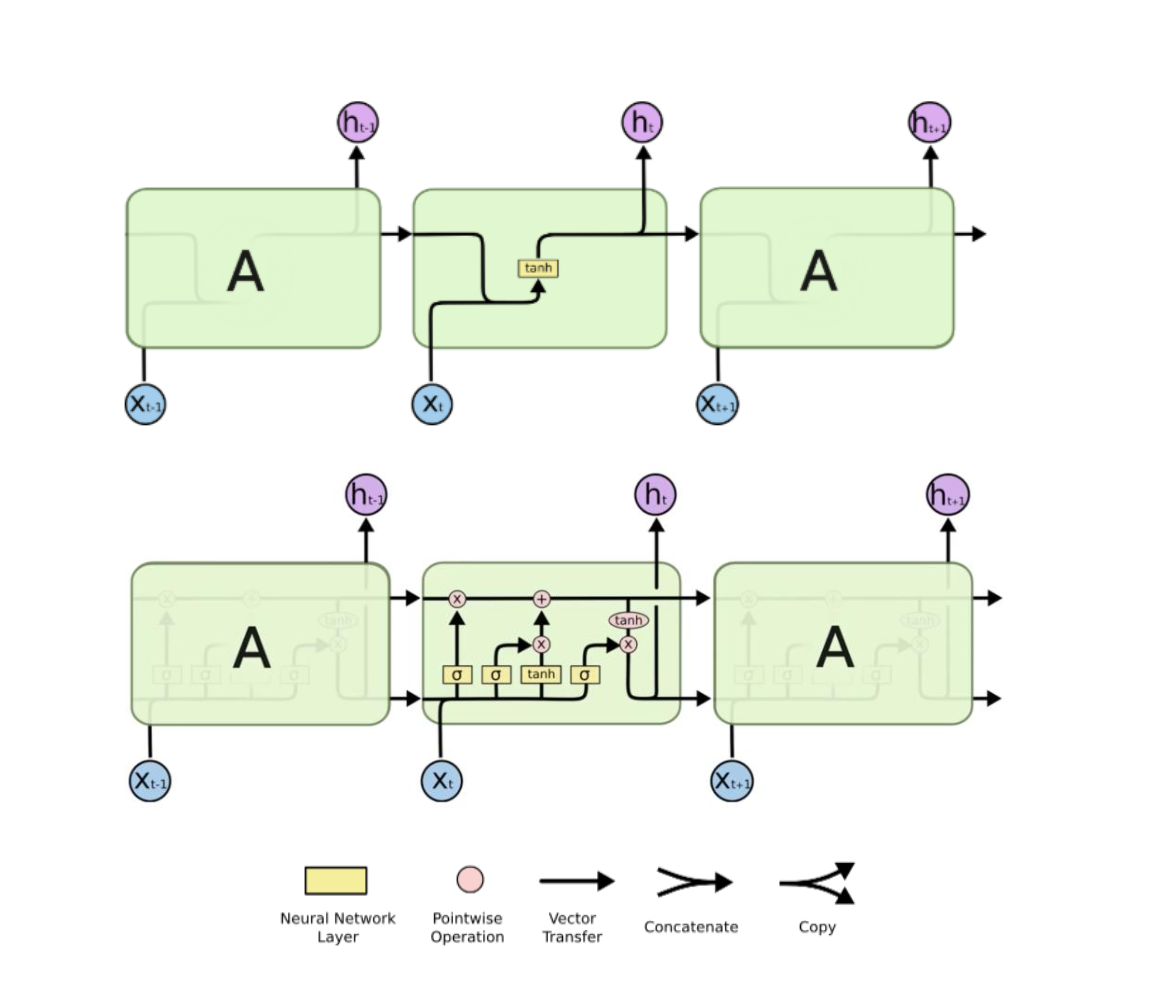
The keypoint of LSTM is that it has two main goals: the original purpose (like classification/prediction) and optimize how much previous information will be passed through.
In the forget gate, it is composed as a neural network layer with sigmoid function. It determines whether to remove the cell, previous one. As sigmoid returns a probability, if it is zero, it means that the model will not convey any information from previous outputs. Otherwise, if the gate output is one, it means that everything will be passed through.
In details,
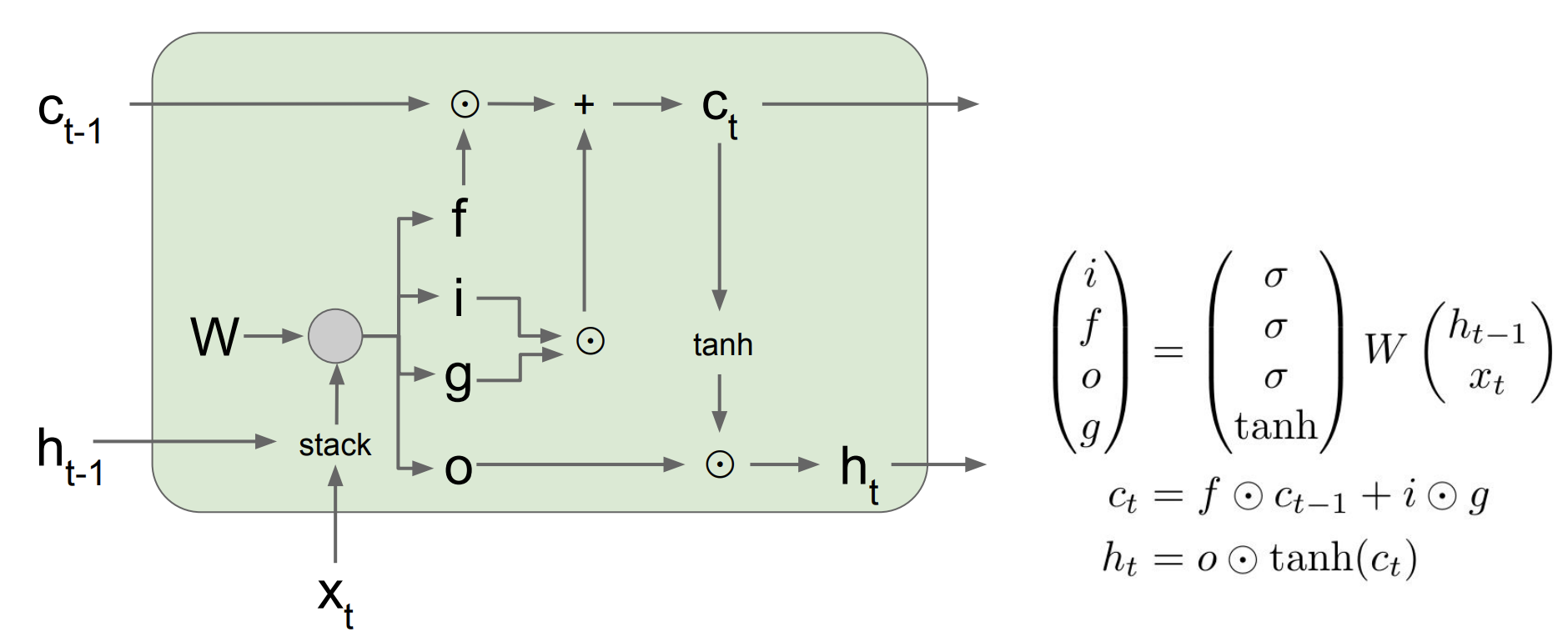
i: input gate, whether to write to cell
f: forget gate, whether to erase cell
o: output gate, how much to reveal cell
g: how much to write to cell
C is a cell state, working as a conveyor belt to convey information.
If the output of the f gate is zero, forget everything - unforget gate actually :)
Through this model structure, LSTM learns what to remember and what to forget!
Notes on the activation function
Why does LSTM use tahn as an activation function?
Sigmoid outputs a value ranging from 0 to 1 so we can consider it as a probability. If taking derivatives in backpropagation, the gradient gets so small that the gradient can be vanished.
On the other hand, tahn returns a value from -1 to 1, which can alleviate the vanishing gradient. That’s why, especially in NLP problems where an input, sentences, can be extremely long, tahn is preferred.
Why do we need LSTM? When?
Let’s say, we want to do sentiment analysis on movie reviews.
I like the movie
If someone writes a review like the above, just simple RNN will be appropriate.
However, if someone says
I….I….I…I..I like movie
which has redundant information (repeated, meaningless words) or way too long, we should take actions on discarding the repeated part, such as a threshold.
In deep learning, however, the goal is to let the model train itself, automatically dropiing unnecessary parts. Vanilla NN abbreviates too much as a sentence gets longer. Also, RNN is not proper in this case since it has only one weighted matrix. LSTM learns how much we need to forget the previous output as being trained; attractive alternative when dealing with long sentences.