This is a class summary of AAI5003, 2021 spring semester lectured by Jinyoung Yeo at Yonsei University.
Let’s say that we want to translate
“the black cat drank milk” in English to French, “le chat noir a bu du lait”.
The former sentence have five words but latter has seven. This is problematic with simple RNN models since the input size and output size are not matched.
Especially in machine translation, we often need to deal with different size of inputs and outputs.
Thus, we need a special model architecture to handle this.
Encoder-decoder model
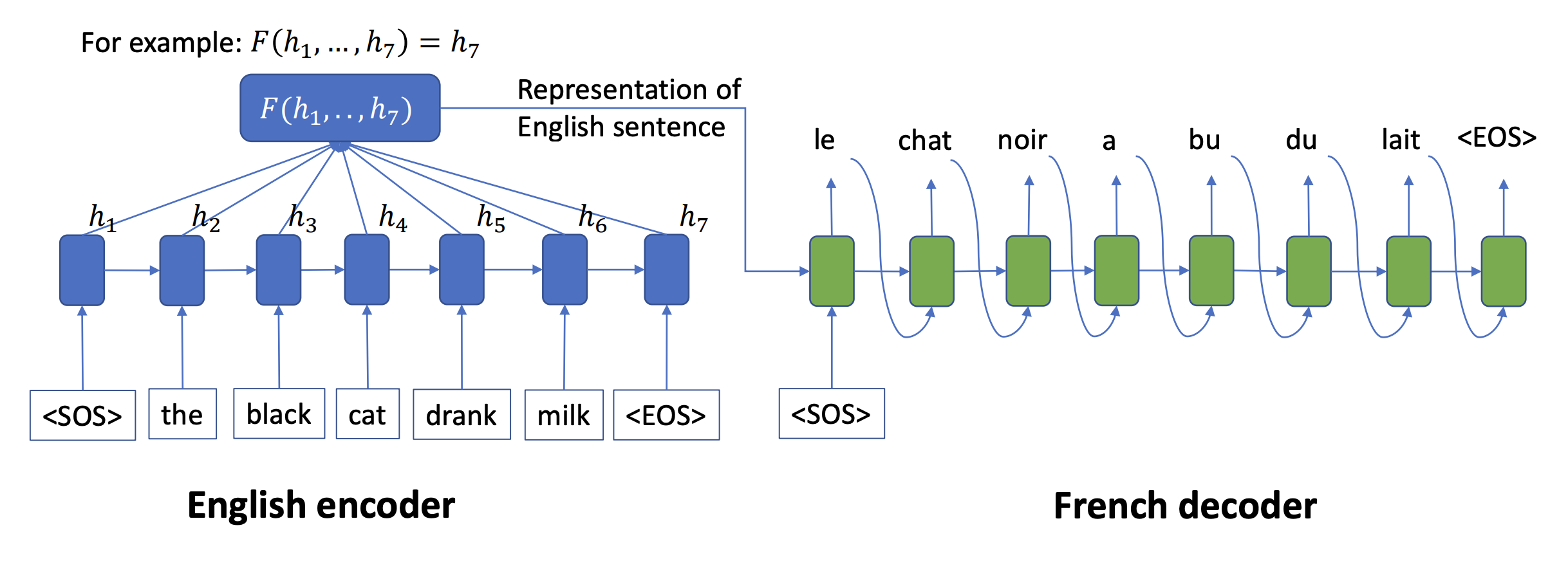
Seq2seq, one of the Encoder-decoder models, is composed of an encoder and a decoder. Encoder literally encodes input data to produce a representation, $h_7$. Then outputs translated sentence in French in this example step by step until *
Teacher forcing
if the prediction from the previous state is wrong, force the next step to learn the right result to reduce error.
Problems with Encoder/decoder model
Even if such rnn-based models are developed to handle a long sentence, it is still problematic since the neural network eventually extracts one single fixed-length of vector to contain all the information. There is a limitation in vector capacity. Especially, if the test data is longer than training corpus, it is still challenging… probably poor model performance.
Attention
To avoid those problems that rnn-based models are faced with, Attention suggests an “attention weight” to note the importance of the word depending on the decoding time step.
Assume that we run a search engine. Then we need to find similar documents with a given query. “Similar” not only represents literally similar but also something related. It might be difficult in defining it technically but if your model solves the given task, finding related documents, well when your model decides some two objects to be related, then those documents can be regarded as “similar”. It could be different from our intuition, though.
Attention Architecture
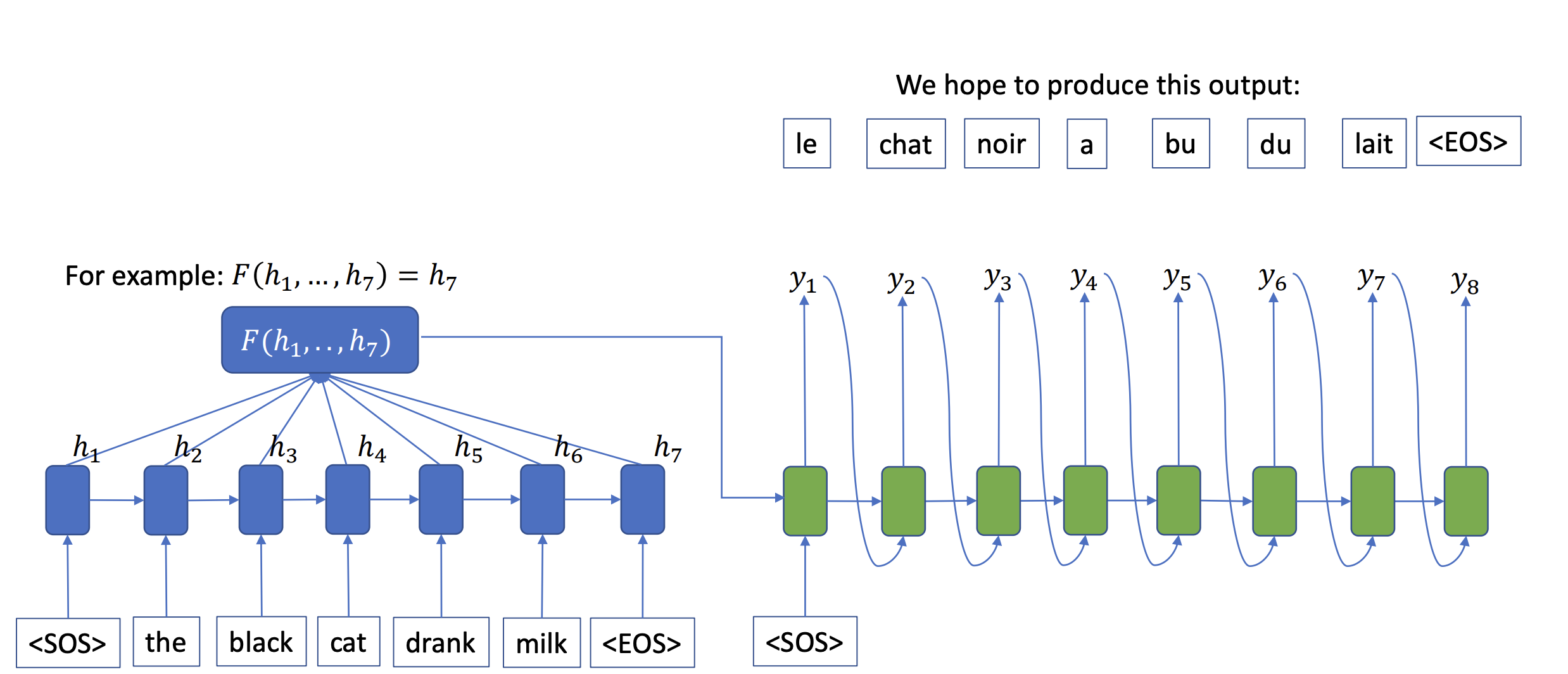
Using the same example above, those green boxes role as a “query” in search engine . The blue one is a “word” in a documents as a search engine result. Our goal is to find the most relevant words in the corpus on the web.Then our search engine should calculate some probabilties to show relevance between a given query and documents. If the score is high, then that word would be located on top of the results.
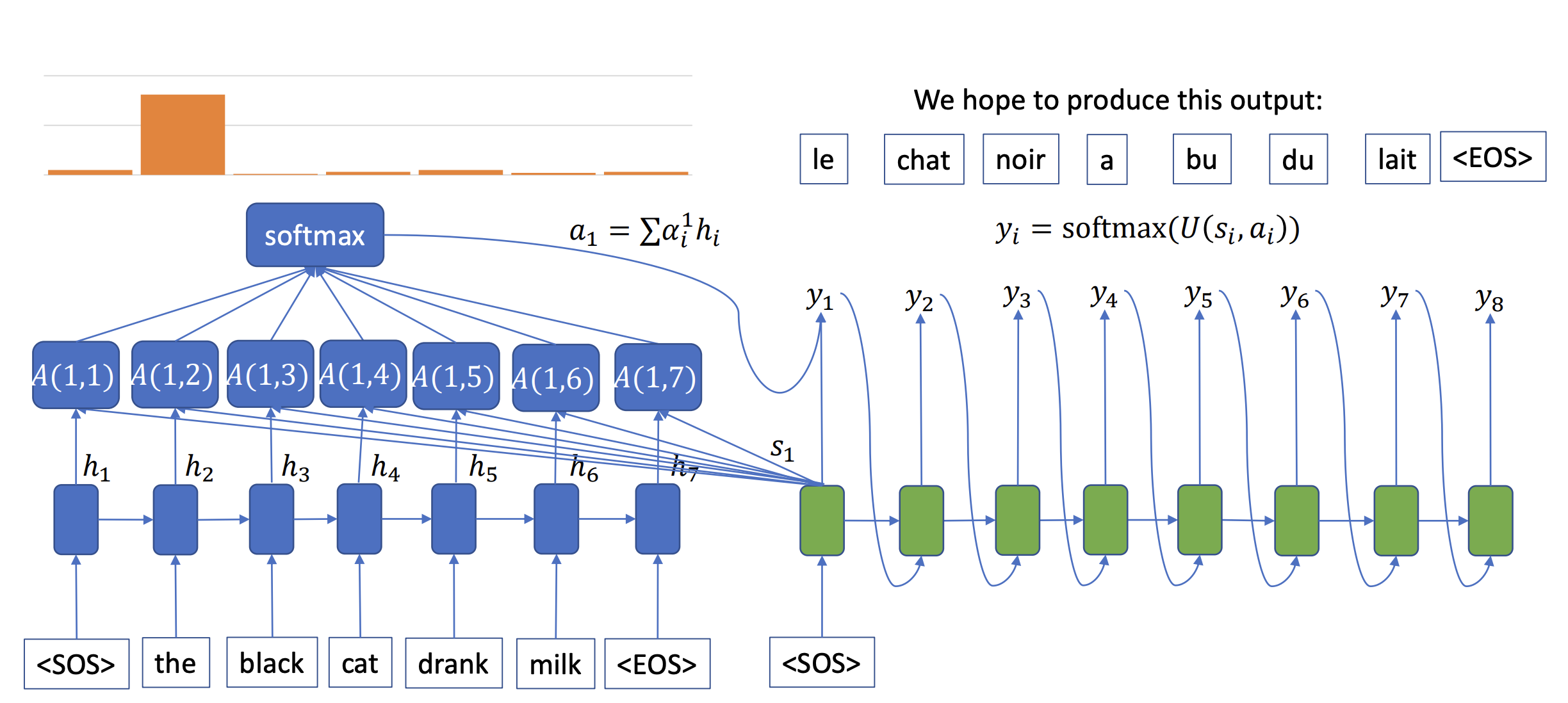
A(1,1) is the attention score of the decoder at time step 1. Each score shows how important a word is at the decoding time step t. Normalize them by softmax function. The graph shows that h_2 is the most important feature of the first green box (see the orange histogram). Each green box has different attention weight parameters, resulting in being able to handle long long sentences. To calculate the attention weight, the attention model uses the word itself and its context.