IDEA
Classification problem 에서
softmax function(p) 의 결과값을 우리가 의미상으로는 어떤 ‘confidence’ 라고 생각을 하지만 (해당 class일 확률이 p이다) 실은 다르다.
ex. softmax output to be 0.86
Then we interpret it as the input will be the “y” by 86% confidence
i.e, we expect 96 are correctly classified when 100 predictions are given.
그치만 그게 아니라고. 0.86은 그냥 softmax output일뿐 저런 의미부여가 안된다고.
그래서 calibration 이라는 과정을 통해 softmax output을 confidence 에 가깝게 만들어주겠다.(q) 왜? Interpret 하기도 좋고 예측이 틀린 상황에 대해서도 우리가 해석을 할 수 있어야하기 때문에.
이게 원래는 문제가 안되다가 - 옛날 모델은 calibration이 잘됐었는데 -
오히려 요즘의 모델들이 calibration 이 잘안돼. 너무 highly confident하더라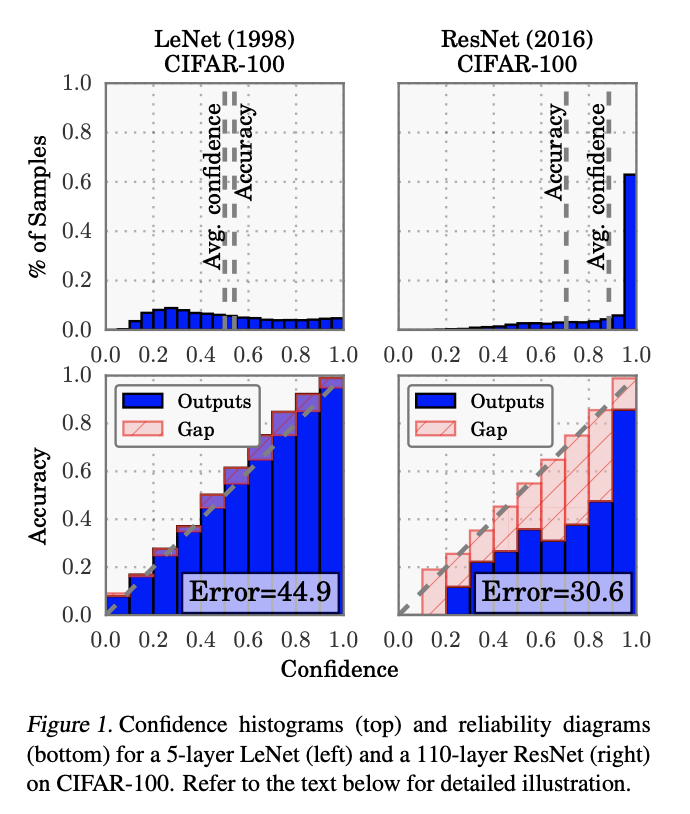
ResNet 같은 경우 accuracy가 엄청 잘나오지만 핑크색 Gap 이 엄청 크다 == poorly calibrated 되어있다. 그래서 이 부분을 보완해줄 필요성이 두각 되었다.
how to measure miscalibration?
그럼 어떻게 miscalibration을 판단할 것인가?
단순하게 생각하면
우리가 앞서서 기대한, 통상적으로 사용되는 softmax output의 역할이 곧 accuracy지 않느냐 - 86개의 예측값이 맞더라! 하는. 고로 softmax output의 평균값과 accuracy의 차이에 집중한다. 이를 줄이면 줄일수록 softmax output 값을 accuracy로 볼 수 있다는 의미기도 하니까.
weighted sum of (softmax output avg - accuracy) –>
Expected Calibration Error(ECE)
difference in expectations between confidence and accuracy
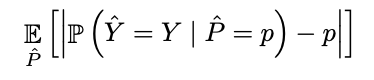
Where Y_hat is predicted class and P_hat is its associated confidence (prob of correctness). our aim is to correct P_hat to represent a true probability.
이게 이제 우리가 궁금한 식인데, 이걸 구하기가 힘들어서 (P_hat)
ECE를 사용. B는 그냥 bin. prediction을 구간별로 잘라서 사용.
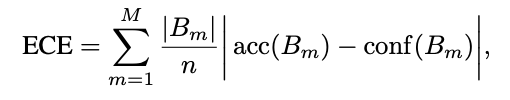
간단하게 생각하면 perfectly calibrated == (acc(B_m) == conf(B_m))
MCE는 위의 diff max 값 찾는거 (최악의 상황), NLL은 다 아니까 생략
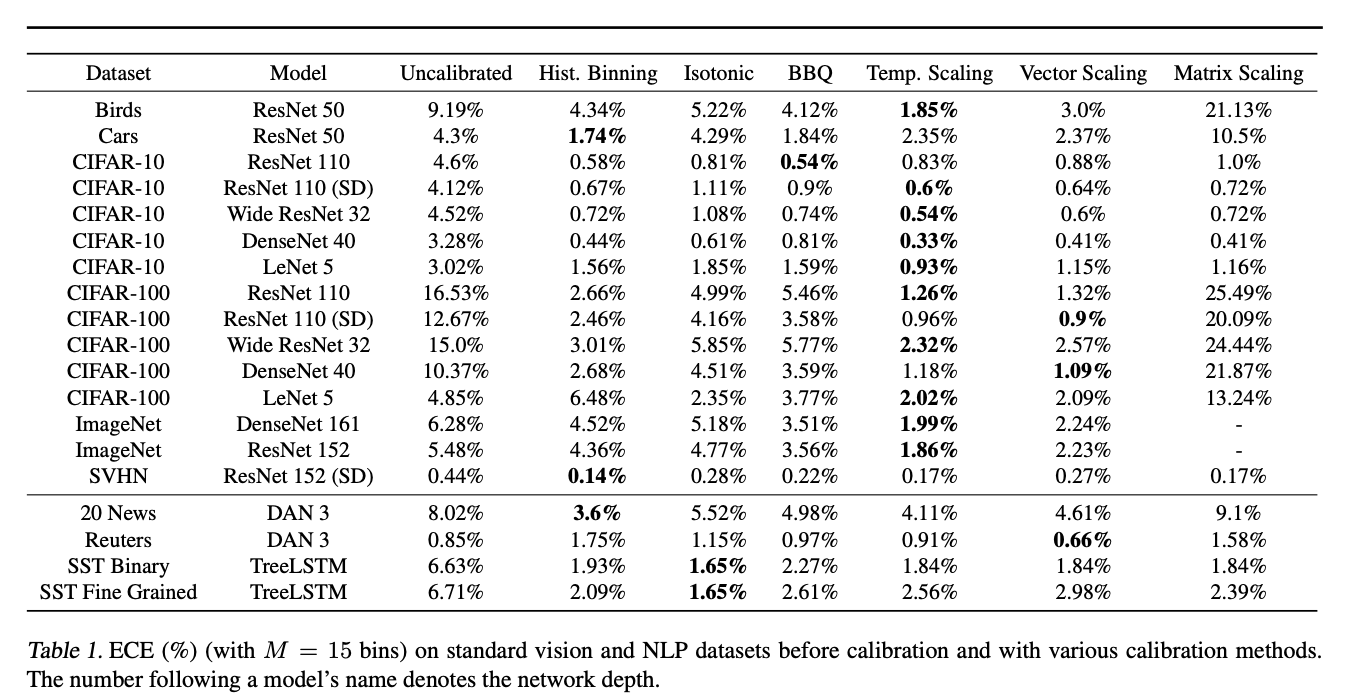
Compare existing methods
calibration에 영향을 끼치는 애들: depth, width, weight decay, bn
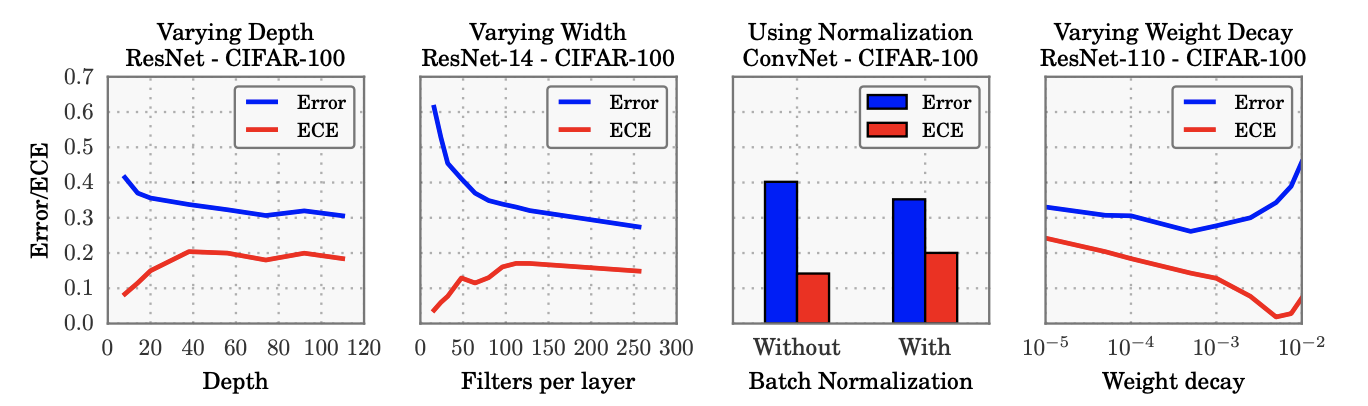
보면 weight decay 빼고 그냥 다 그래. 심지어 bn은 쓰니까 악화됨. 그리고 weight decay는 점차 안쓰는 추세라…
다른 방법들도 소개하는데 결론은 아래.
Temperature Scaling
softmax를 단순하게
temperature scaling 으로 조금 완화시켜보자. 그냥 단순하게 정말정말 단순하게 single scaling parameter T를 모든 class 에 대해서 사용하는거.
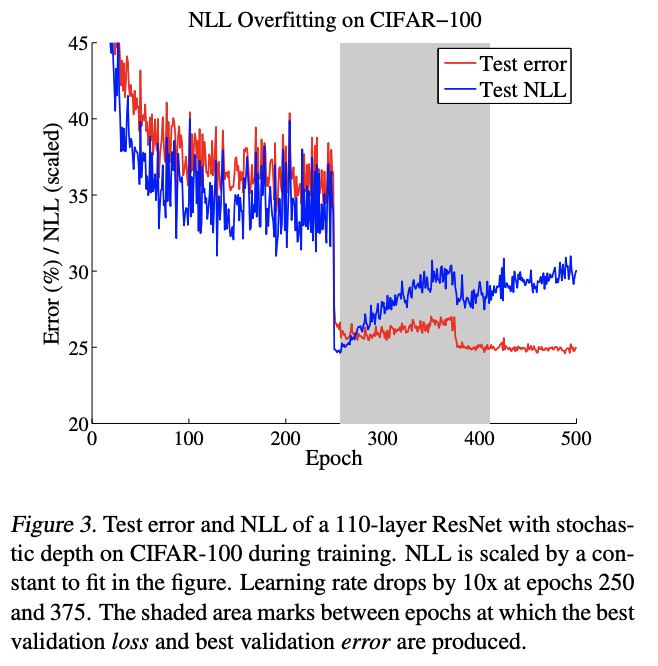
Test NLL이 overfit 하지 않게 끊어줘야 calibration이 잘된다. 저 grey area에 파란 선을 낮춰주고 싶은거야. 근데 early stopping은 아니고 다 한다음에 single scaler로 밑으로 내려버려. 약간 over confident 된 애를 완화시켜보자.
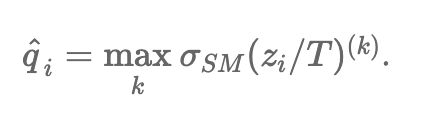
그럼 T를 어떻게 설정하냐? NLL on validation set
한계점: validation set의 quality가 굉장히 중요하다. need to assume that train, valid and test datasets are drawn from the same distribution. 막 uncertainty 한 상황을 detect 해주는 bin 같은건 아니고. 우리가 얻은 결과에 대해서는 인정을 하는 느낌?
아래 그림보면 CIFAR-100 데이터로 calibration 결과 비교하는 건데, 핑크색 gap이 작을수록 well calibrated 라 할 수 있고, temp scaling이 제일 잘된걸 알 수 있다 + 그리고 단순히 더 좋다! 뿐만 아니라 computational cost 도 제일 부담이 적더라. 단순히 scaling이니까. 쉽고 빠른데 성능이 제일 좋다.
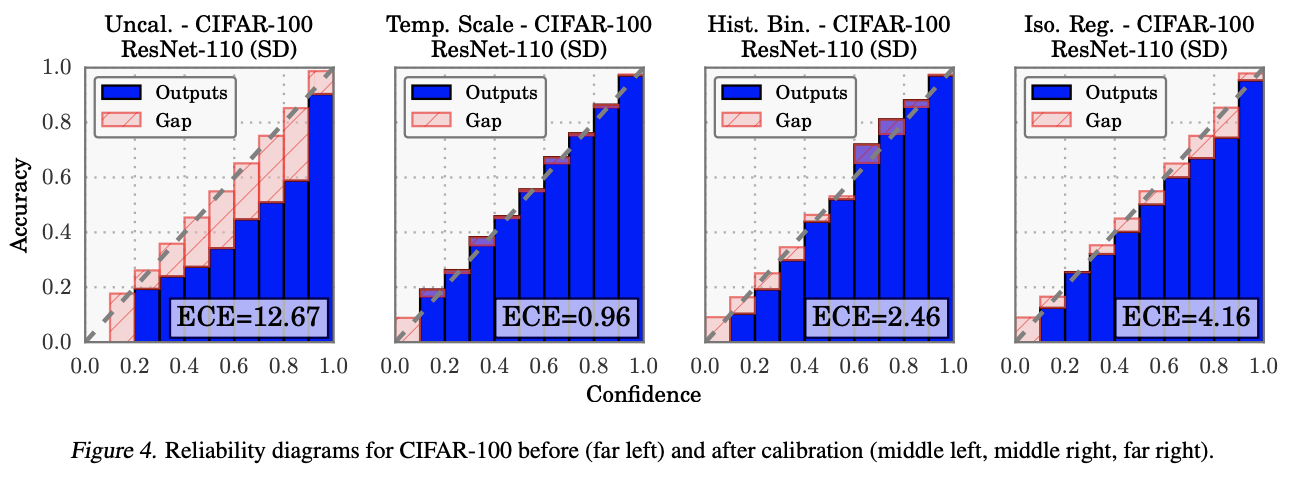
결론: 괜히 쓸데없이 복잡한거 할 필요도 없다. temperature scaling 이면 surprising 한 결과를 얻더라~