This is a class summary of AAI5003, 2021 spring semester lectured by Jinyoung Yeo at Yonsei University.
Transformer with Self-Attention
- It works as an alternative to sequential methods such as RNN
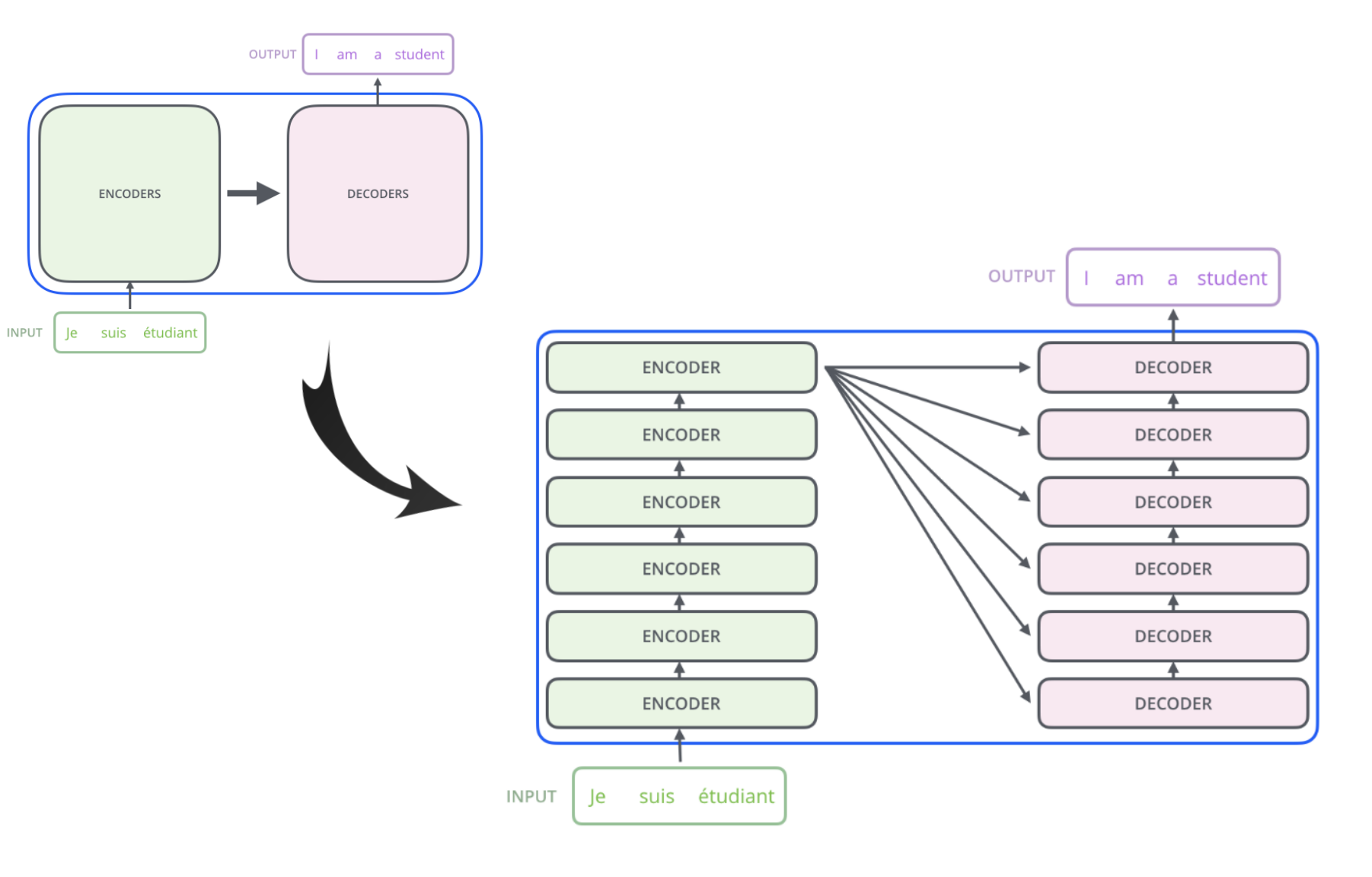
- Transformer consist of encoder to input a sentence and decoder to output a translated sentence as seq2seq but it can stack up each layers like the above figure (diff with seq2seq)
- In the above figure, the model stacks six encoders and decoders (where the number of stacked layers is a hyper-parameter and six is used in the “Attention is all you need” paper)
- Unlike sequential models, **Encoders do not share weights (independent) **
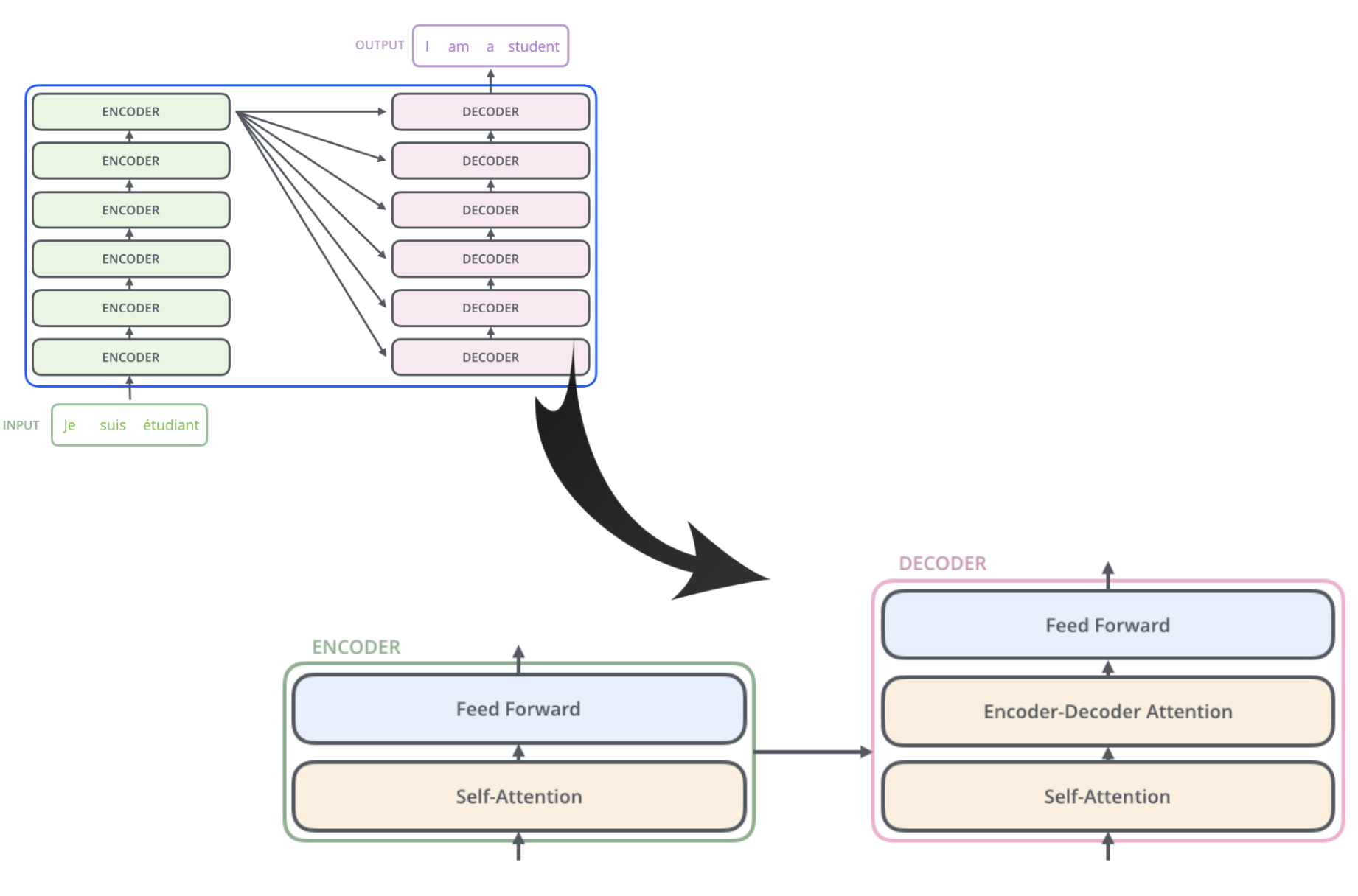
Encoder consists of two sub-layers: self-attention + feed-forward nn
- Self-attention makes representation of a target word as a weighted sum of other words (context)
- Self-attention focuses on relationships among source words
- Then the feed-forward layer aggregates outputs from self-attention
Decoder = self-attention + encoder-decoder attention + feed-forward nn
- Encoder-Decoder Attention? decoder works as lstm based seq2seq(???)
- Encoder-Decoder Attention focuses on relationships between source words and target wrods
The main difference with RNN
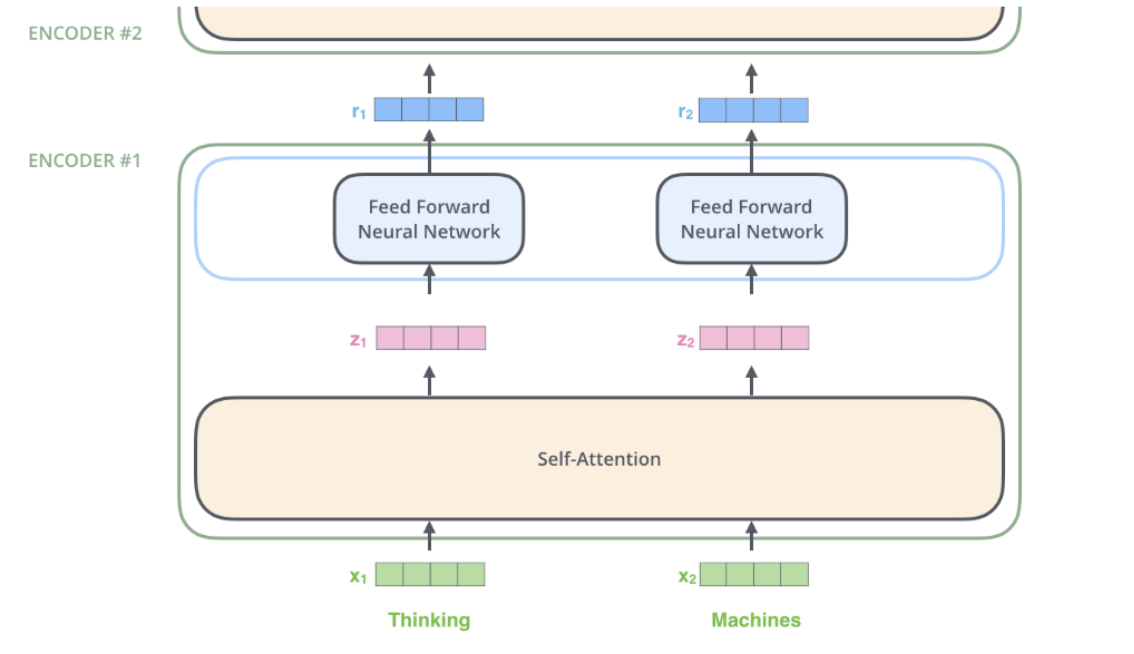
- Each word(Thinking, Machines in this figure) goes through its own path
- No need to accumulate historical data
- Works in a “parallel” manner
What is the Self-Attention?
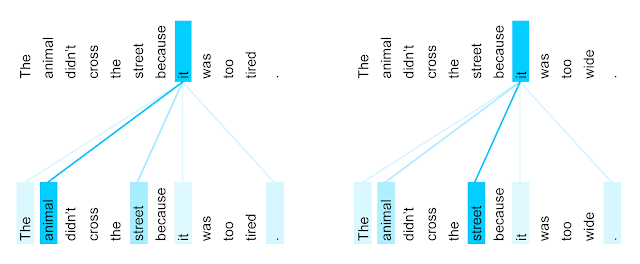
- How to find out what “it” means?
- Sequential methods need to accumulate previous words (The, animal, …, because)
- It accompanies too many noises, causing inefficiency
- If the sentence is much longer, LSTM has difficulties in holding “animal” (because “it” points “animal” in this example) until “it” appears
- Actually, sequential models only focus on previous words in a sequential manner (Bidirectional LSTM might be better but still stuck with those problems)
- However, self-attention allow us to point out other positions (words) in the sentence
- It aggregates representations of “surrounding words” by attention weights and bakes them into a target representation
Self-Attention in Detail
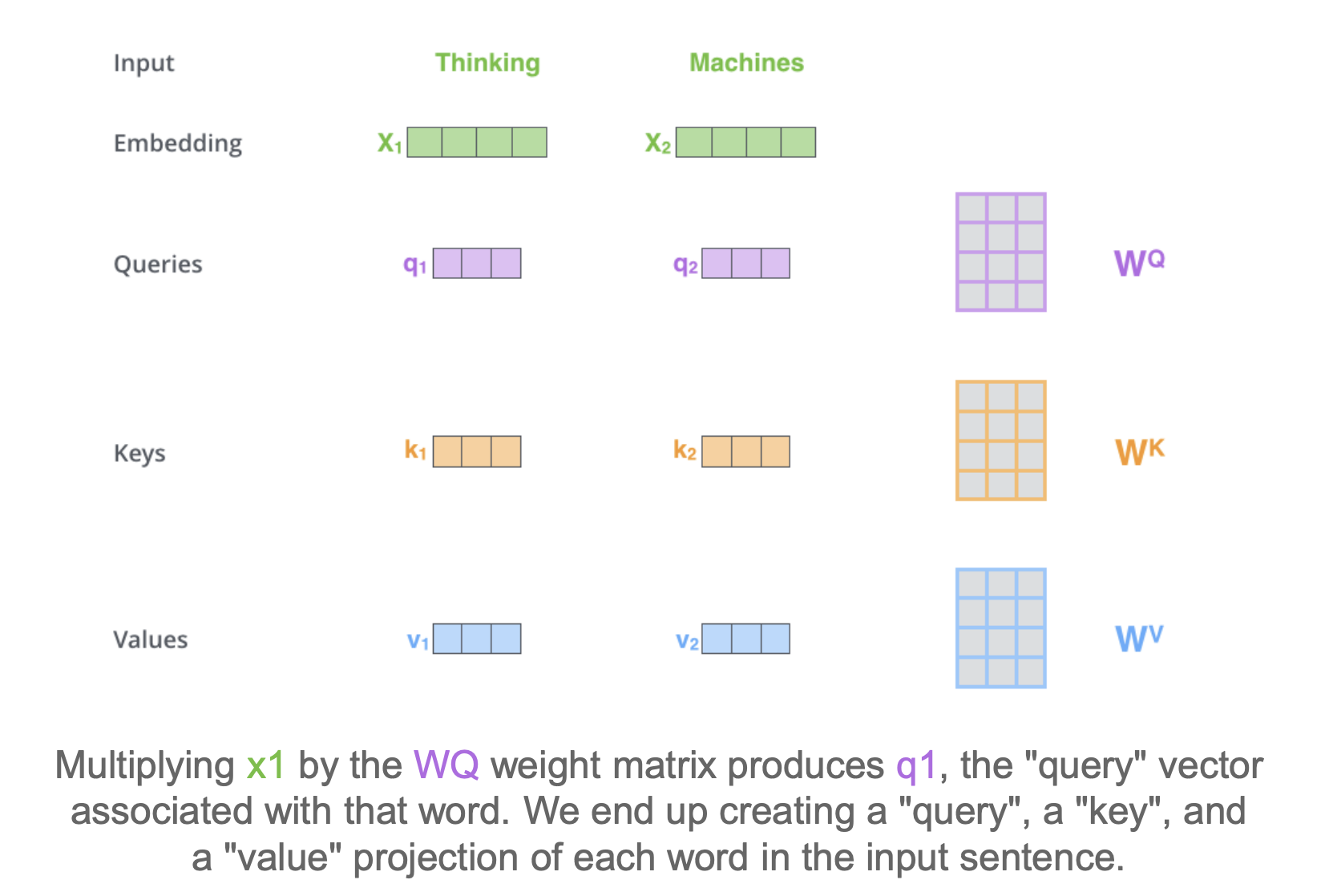
- Given a set of embedded words, $X_1$ is a word in the input sentence
- $W_Q, W_K, W_V$ are trainable weights and
- $q_1 = X_1 \times W_Q$
- $k_1 = X_1 \times W_K$
- $v_1 = X_1 \times W_V$
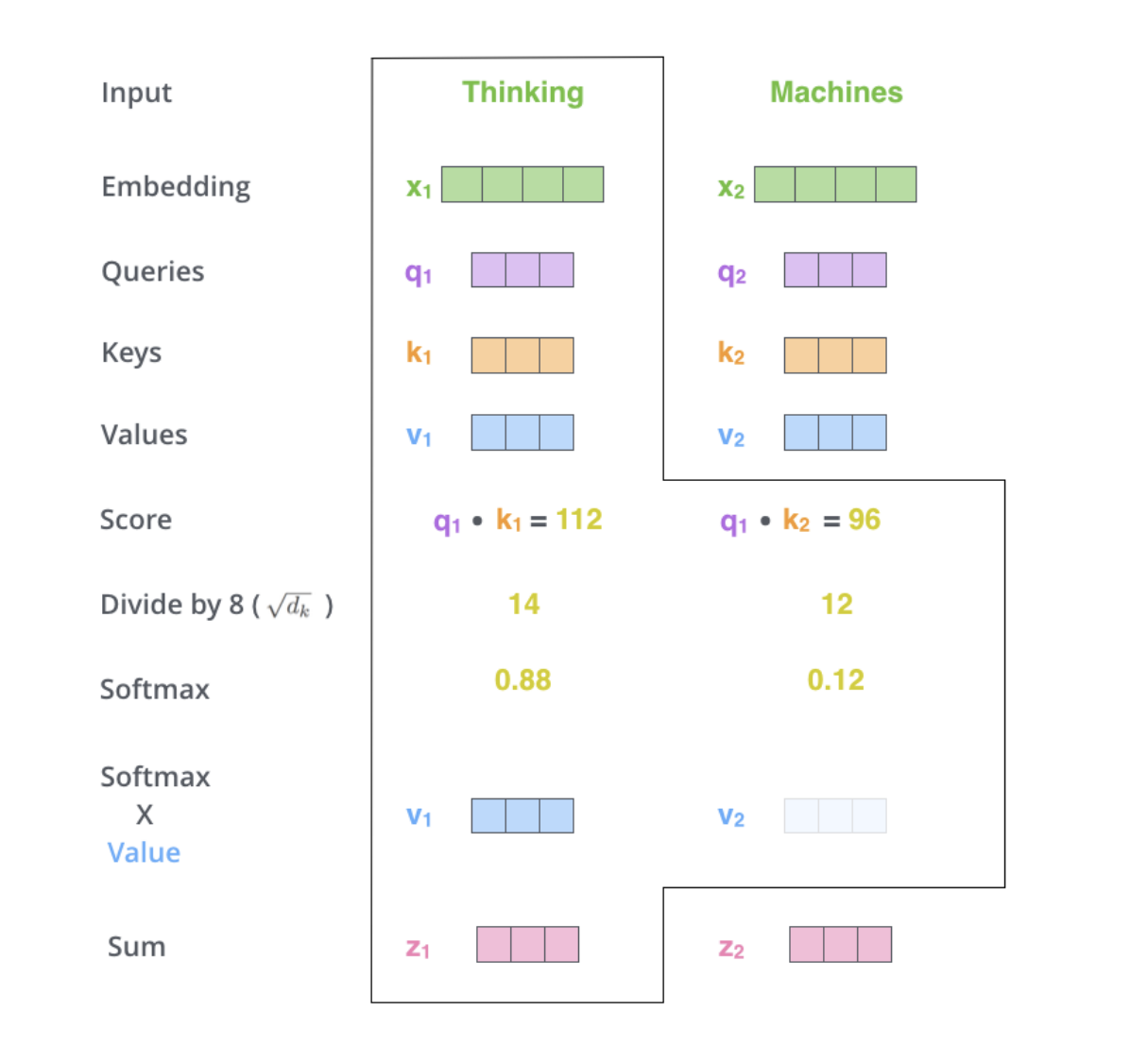
Check step by step:
-
For the given input word $X_1$, “thinking”,
-
Attention module scores similarities between every “keys” and the given “query”
$q_1 \times k_1$ and $q_1 \times k_2$
- Then scale it and apply softmax on scores
- It is natural that the word, “thinking”, itself has the highest score
- Depending on the similarity score, multiply it to “values” to update them
- Sum up updated values with weights
What purposes are those queries, keys and values for?
- ex. Search engine
- Query is how to represent a searching word
- Key is how to express correlations with other documents (telling which document is more relevant to our searching word)
- Value is a way to express weights of each document
However…
-
Limitations: if training dataset is not enough or gpu is not available, poor model performance –> transfer learning can solve this (later to be covered)
-
Without pretrained modules, diffifult to implement
Multi-head attention
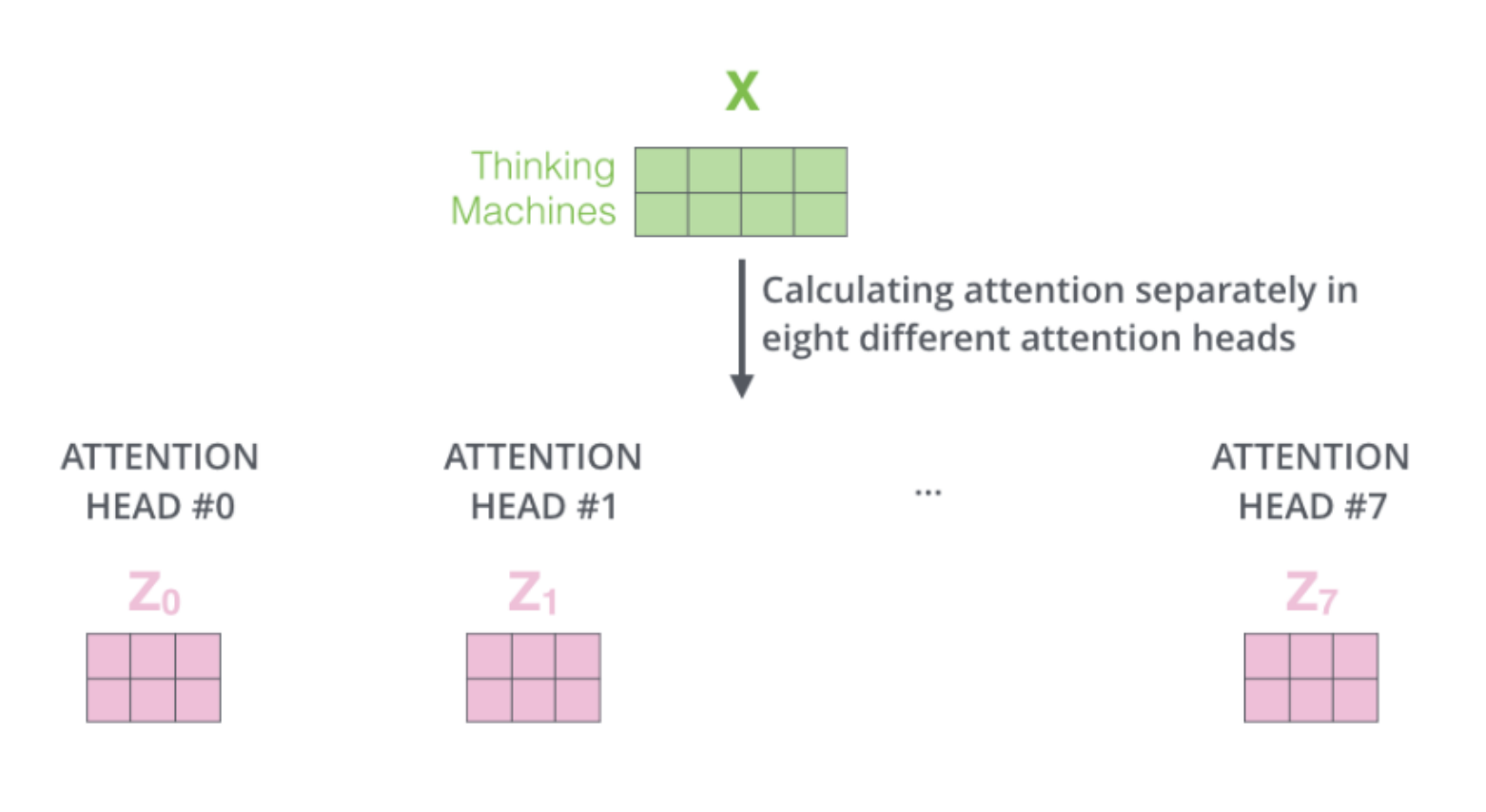
-
The idea is: there are diverse ways to interpret a sentence
- As a sentence gets longer and more complicated, it is hard to tell the writer’s intent and also depending on a reader’s background, the same sentence can be interpretated in different ways
- Thus, by using multi-head attention architecture, we allow our model to learn with a broad perspective
Reference
- https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
- https://wikidocs.net/31379