BERT Architecture: multi-layer bi-directional transformer encoders
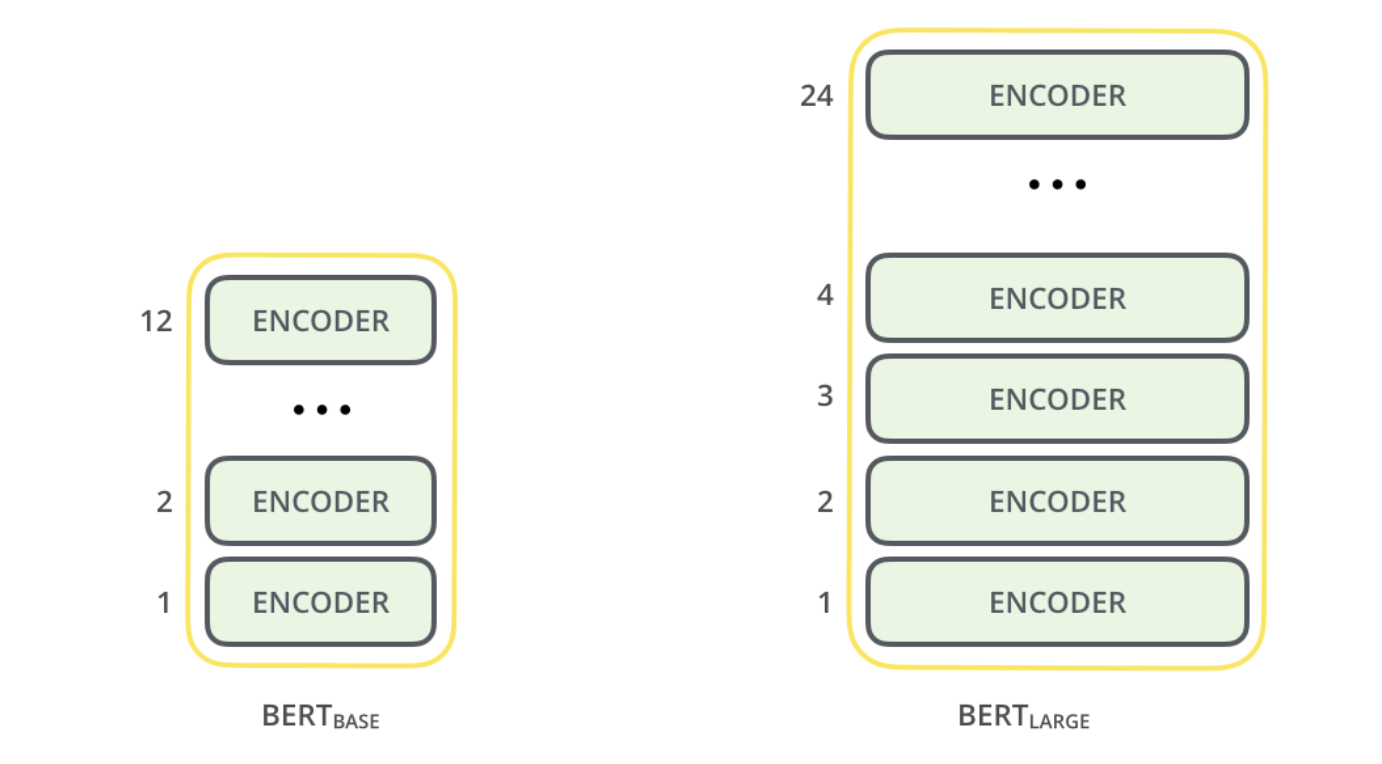
There are two BERT model sizes: BERT LARGE, BERT BASE
- Basically similar looking - multi-layer bi-directional transformer encoders
- We need to remember some numbers - common sense for NLP engineers
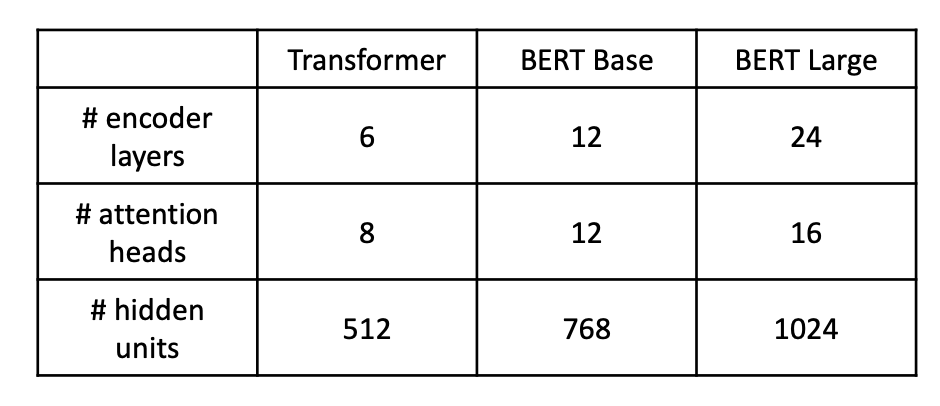
- Same as transformer but twelve layers
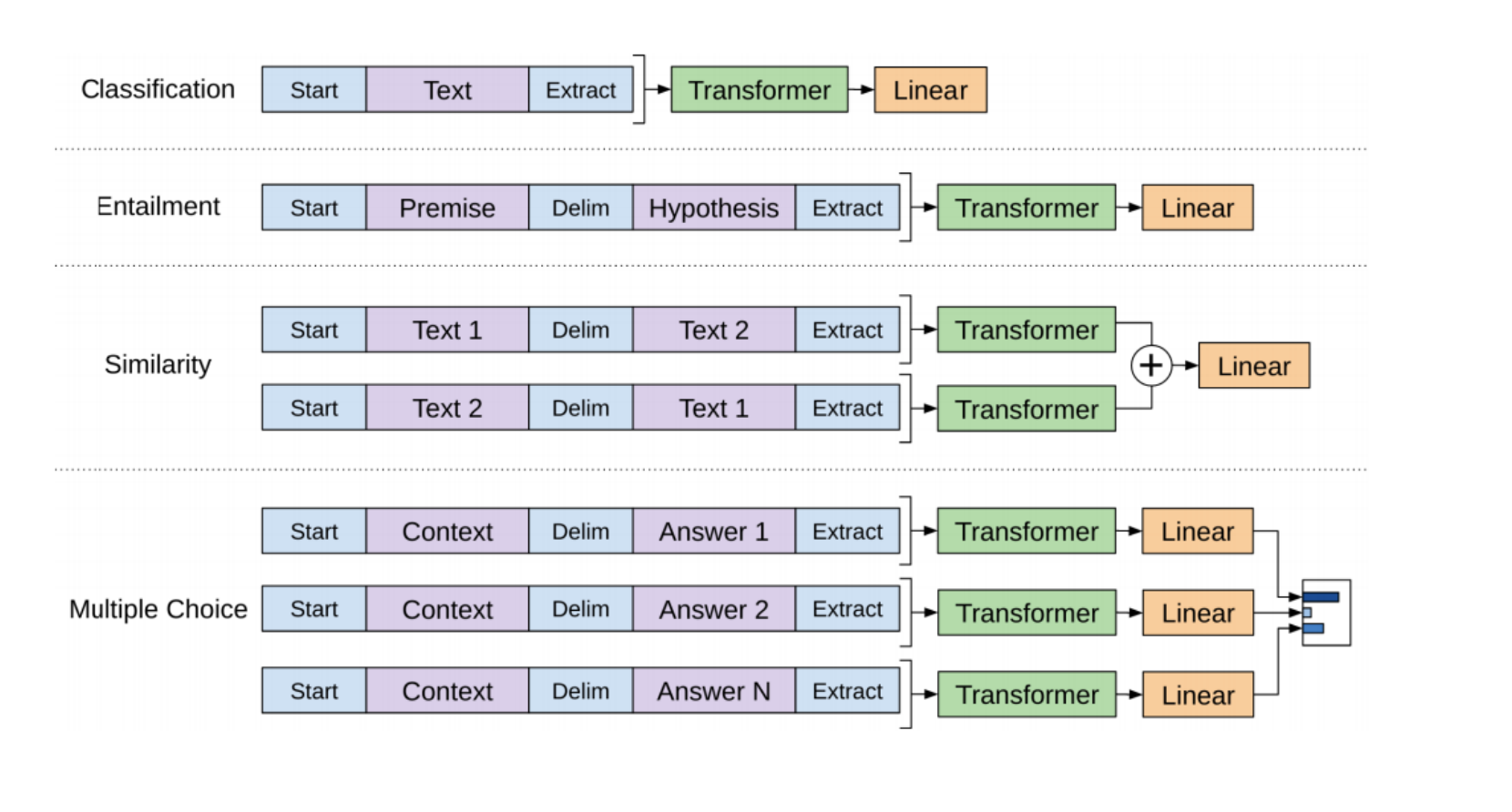
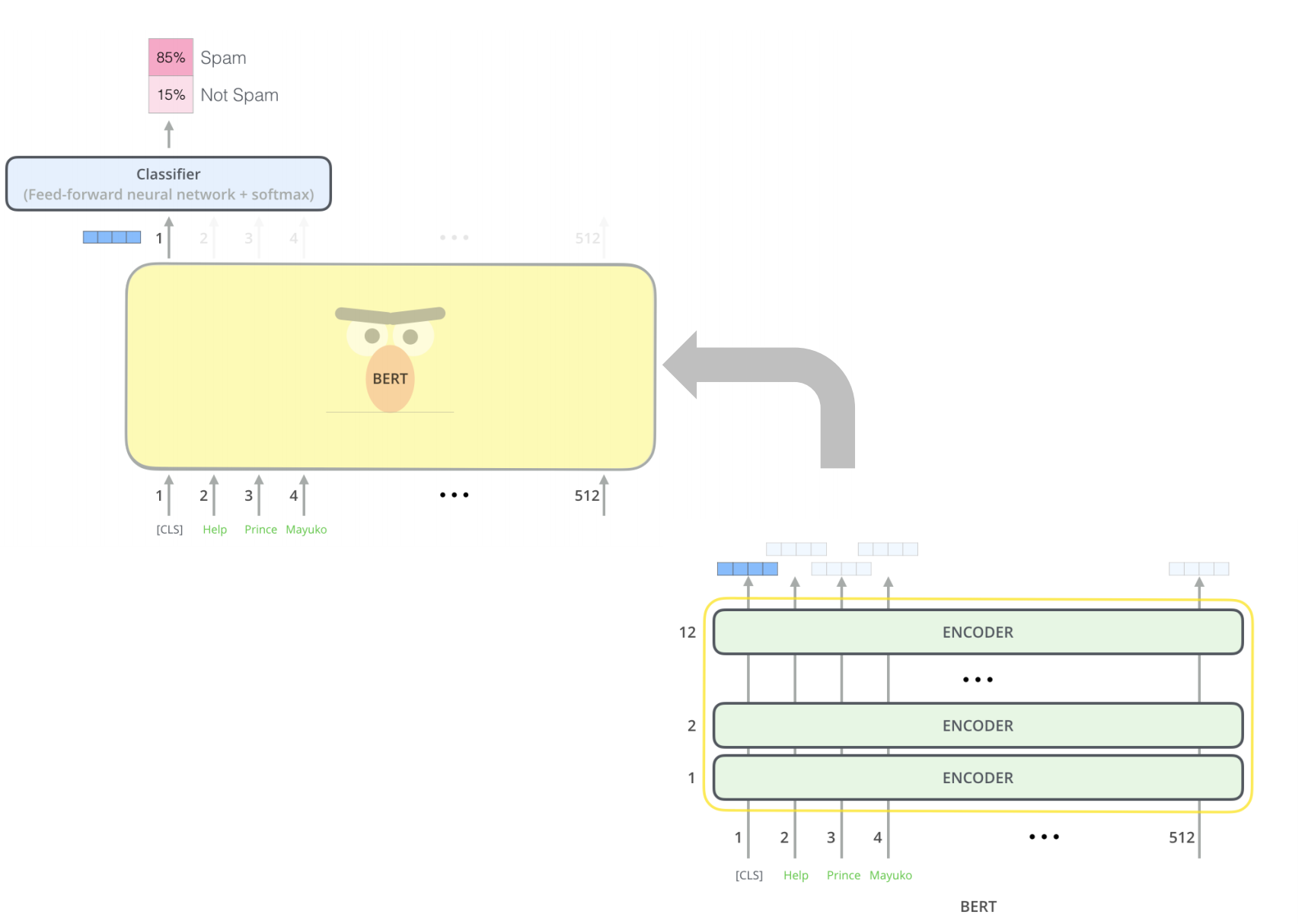
- For the figure example, we only use the output at the first position passed from the first input token
for simple classification. We expect that this first output contains all the information needed for classification via self-attention mechanism.
BERT consist of two parts: Pre-training and Fine-Tuning
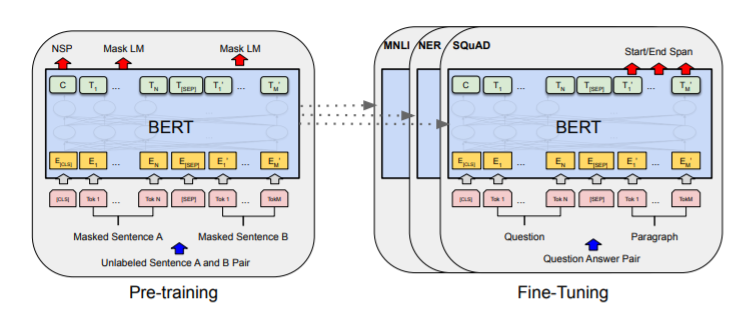
1. Pre-training Procedure
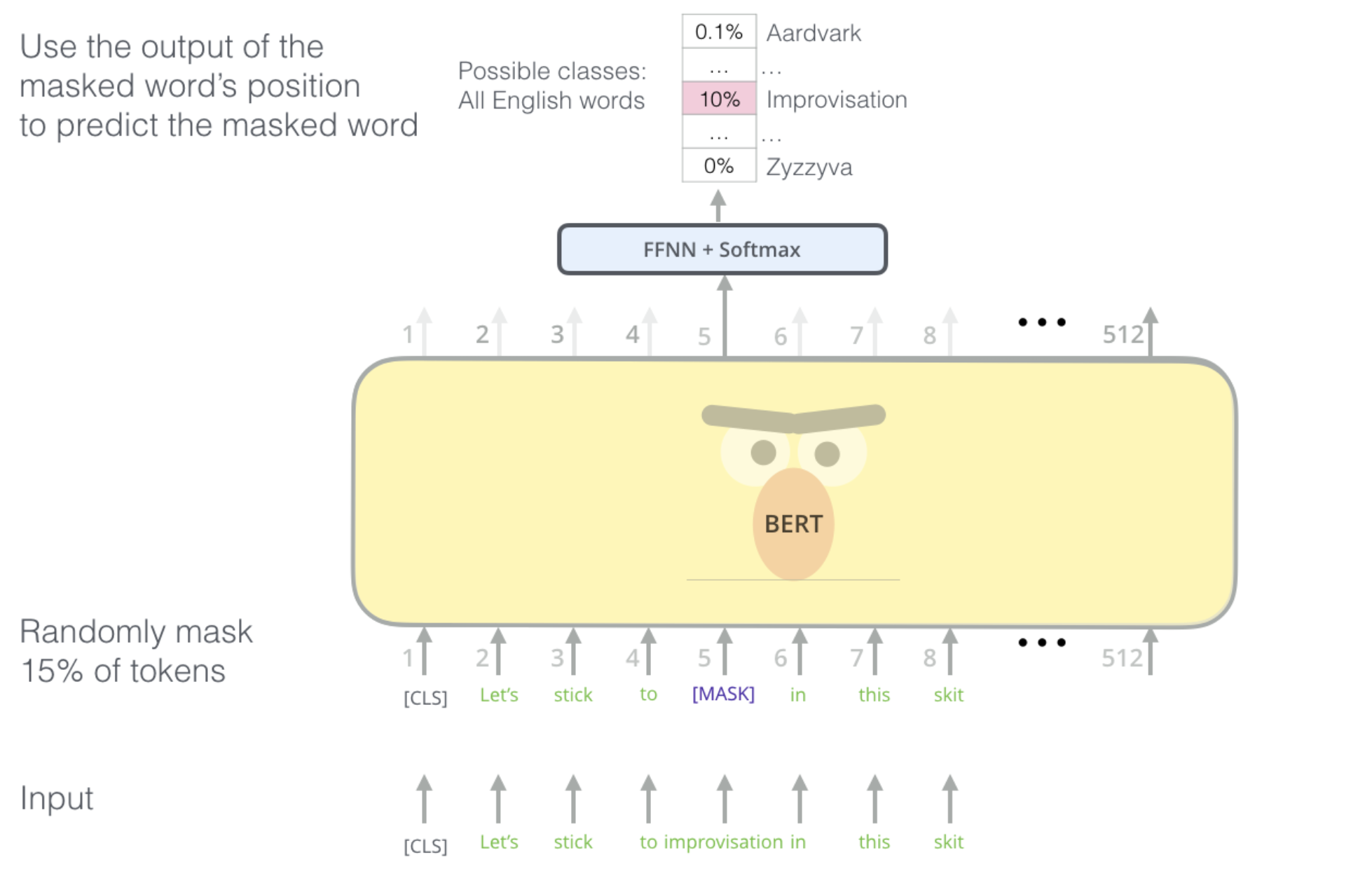
Task #1: Mask LM (MLM)
-
randomly mask out a word in the given sentence to predict it
-
but with those rules:
-
80% of the time: replace the word with [MASK]
-
10% of the time: replace the word with a random word
–> to perturb our model to be more robust
-
10% of the time: leave the word unchanged
-
not appropriate for generative tasks but good for classification ones
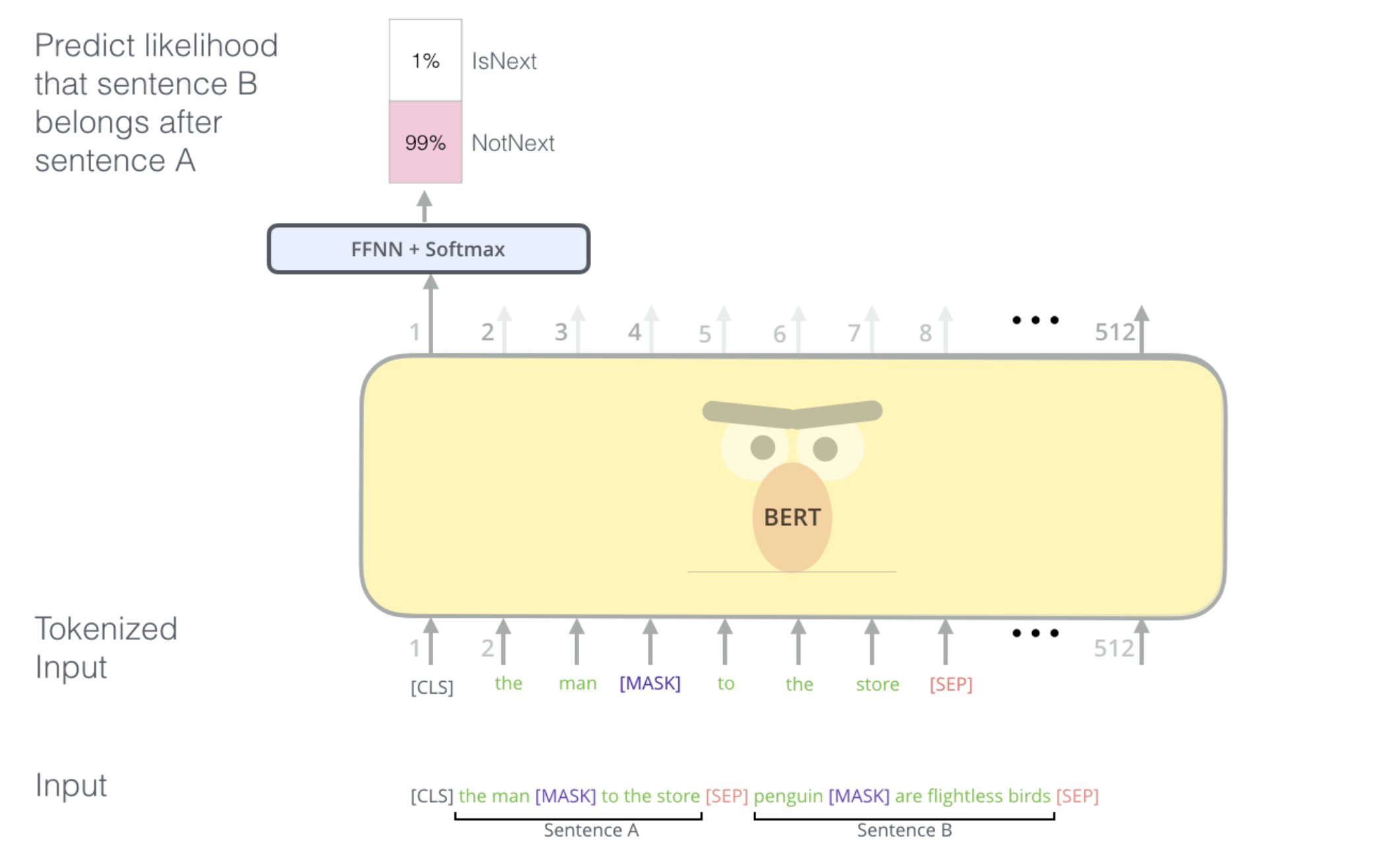
Task #2: Next Sentence Prediction (NSP)
- When two sentences (A, B) are given,
- BERT is trained to predict a sentence B belongs after a sentence A
- This helps BERT to perform well in QA tasks where relationships between two sentences are important
- For embedding two sentences, BERT needs three embedding methods:
- Token Embedding: original word embedding including
, - Position Embedding: addressing position information as $E_1, E_2$
- Segment Embedding: separating out two sentences as $E_A, E_B$
- Token Embedding: original word embedding including
2. Fine-Tuning
-
Slightly changes pre-trained weights appropriate for the given task
for example, add a classifier layer to BERT for sentence classification problem.