Contextual Representation
Static representation such as Word2Vec, Glove considers a word as a single vector with a single fixed meaning.
However, in many cases, a word has different meanings depending on its syntax, semantics and context, so that we are needed to learn its dynamic representation.
–> Contextual representation such as ELMo, BERT, GPT thinks that a single word can have multiple vectors

ELMo: Embeddings from Language Models
ELMo uses bi-directional LSTM (pre-)trained with language models on a large text corpus
By solving Language Modeling (LM), we expect our new representations to learn which parameters are proper and needed for conveying multiple meanings.
Language Modeling : Not for downstream taskes that require human supervision, a task to predict the next word in the given corpus.
For human to make an exam problem, we need to read materials and solve the problem. Like this, ELMo use LM to learn word embeddings. Since there are tons of large scaled corpus availlable for LM, we pre-train the bi-directional model on those data to learn contextual representation - ELMo.
Bi-directional language models
Bi-directional LM = Forward LM + Backward LM
When a sentence of t tokens is given,
-
Forward LM predicts “which word will come next” at time t+1
-
Backward LM reverses - it predicts the previous word at time t-1
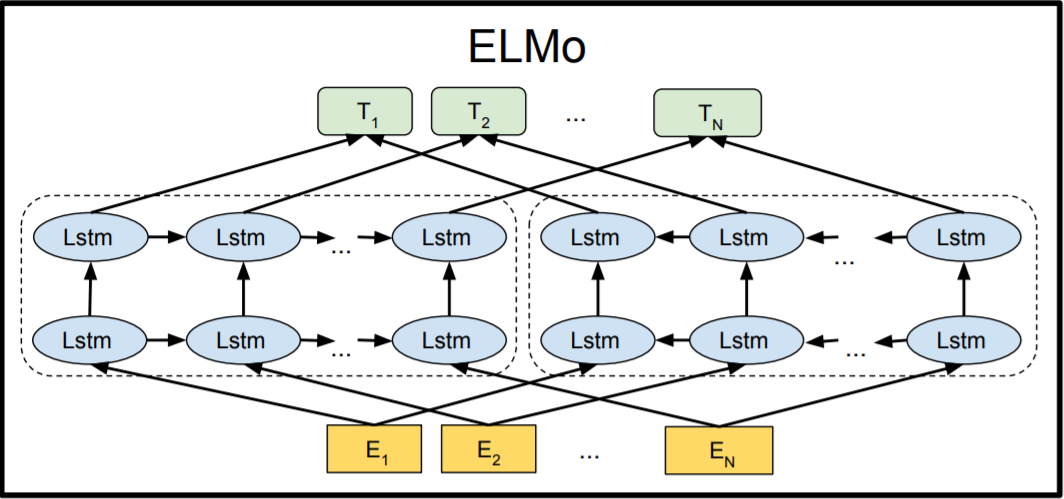
Then ELMo aggregates the hidden states of the forward and backward parts (concatenate and weighted sum) to get a contextual representation of a given word.
This bi-directional structure helps ELMo to learn the whole sentence, leading to learn contextual embedding vectors, not static ones.
Why do we need backward LM?
It might seem that backward LM is meaningless in practical environment since we are interested in predicting the “next” word, not the previous one. However, in ELMo, the purpose of the backward LM is not to train the LM well but to train for train. LM is not the purpose itself but a ‘method’ to train well.
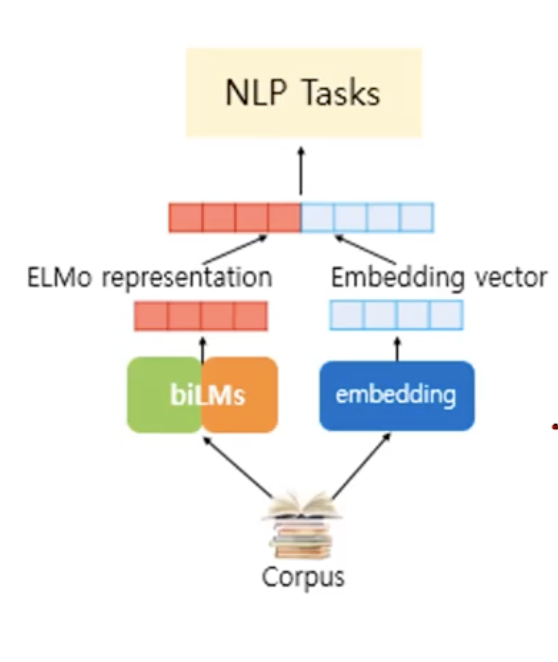
ELMo application after pre-training
We can use the ELMo representation itself or combine it with our own embedding vectors to reduce the computational cost.
Reference
- https://arxiv.org/abs/1802.05365
- https://wikidocs.net/33930
- http://jalammar.github.io/illustrated-bert/
- https://www.slideshare.net/shuntaroy/a-review-of-deep-contextualized-word-representations-peters-2018