Model Architecture
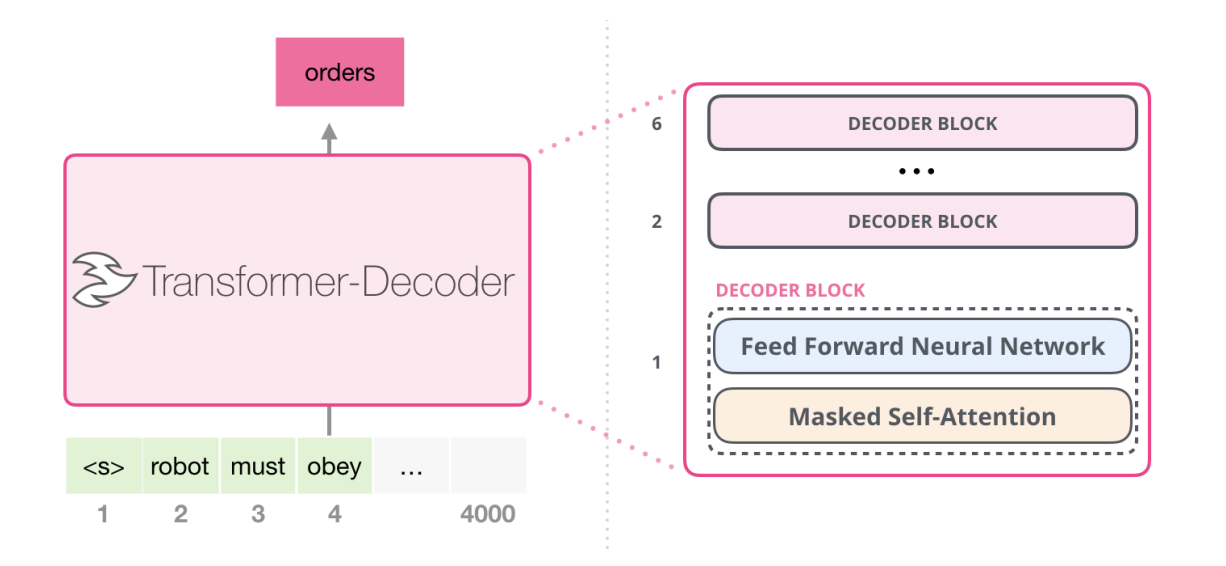
-
Multiple layers of transfomer decoders
-
Similar looking with Transformer, BERT
Masked Self-Attention
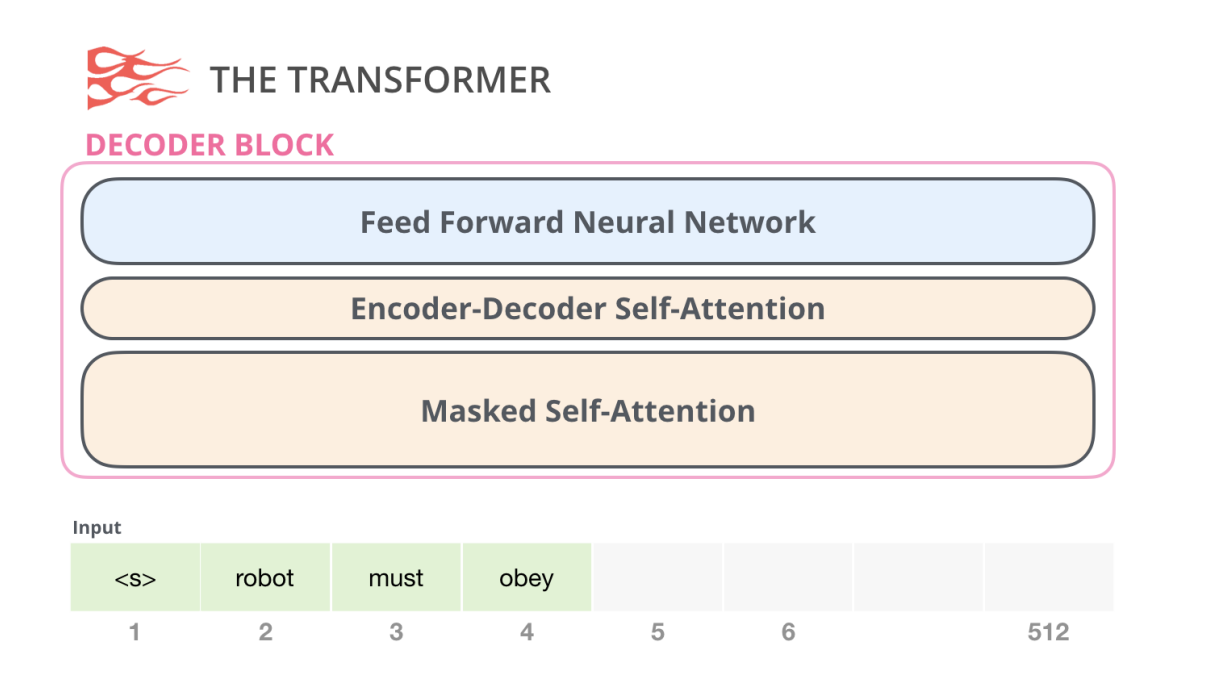
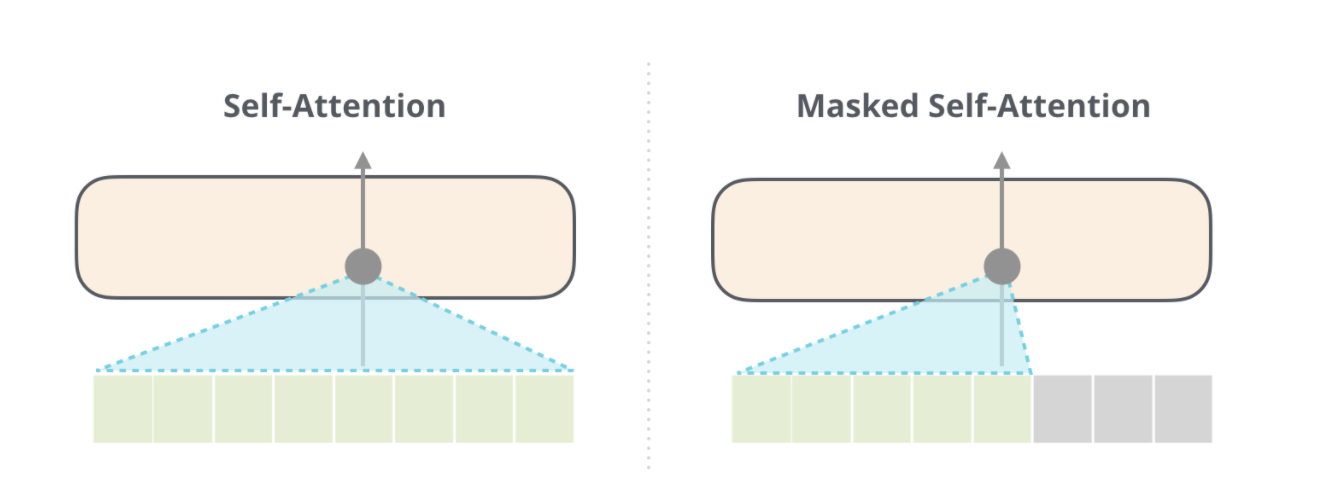
-
Unlike self-attention,
-
Mask out words on the right side of our target word
-
due to its structure, we also call it auto-regressive model: predict next word step by step
-
this seems more natural since we have no idea what next words will be in practical problems
-
leading to improve model performance in generative tasks
How GPT-2 can work on multiple tasks without fine-tuning?
- Both original input and ‘task’ as an input
- Ex. “how are you” + translate to Korean
- Let our model know the task for better model performance
GPT vs BERT
GPT:
- Pre-trained to predict the next word
- Uni-directional
- good at generating tasks
- layers of decoders only
BERT:
- Mask out the word in the middle and predict it
- Bi-directional
- good at understanding its meaning
- layers of encoders only
Suppose that we want to predict “거기” in the below sentence.

GPT only refers to “어제, 카페, 갔었어” (not in sequetial manner though), while masking out all tokens coming up after our target word. On the other hand, BERT uses all the tokens.
In both models, however, basically atttention mechanism is implemented, being trained to learn “important” word in the candiate pool via updating the whole model.